
What is Crawlspace ?
Crawlspace est une plateforme conçue pour les développeurs, visant à simplifier le web scraping et l'extraction de données. Que vous construisiez des applications, entraîniez des modèles d'IA ou collectiez des informations, Crawlspace vous permet de collecter des données structurées, fraîches et à grande échelle, sans les tracas de la gestion d'infrastructure.
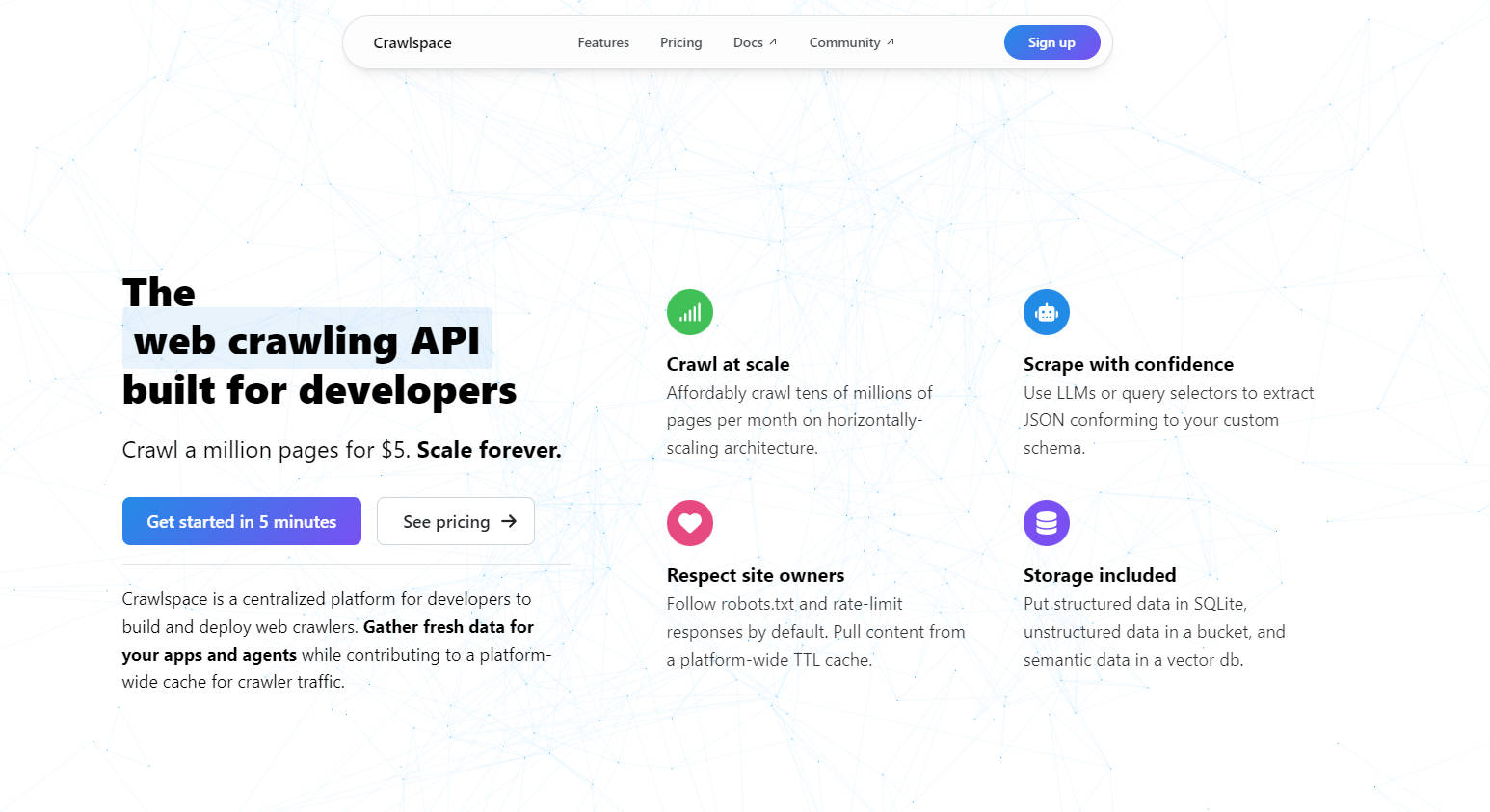
Fonctionnalités clés
? Exploration à grande échelle
Explorez des dizaines de millions de pages par mois à un prix abordable. Grâce à une architecture à scaling horizontal, vous pouvez développer vos projets sans vous soucier des goulots d'étranglement de performance.
? Extraction de données intelligente
Utilisez des LLM ou des sélecteurs de requête pour extraire des données JSON conformes à votre schéma personnalisé. Que vous récoltiez du texte, des images ou des métadonnées, Crawlspace garantit que vos données sont propres et utilisables.
? Exploration respectueuse
Respecte robots.txt et limite le débit des réponses par défaut. De plus, tirez parti d'un cache TTL à l'échelle de la plateforme pour réduire le trafic redondant et respecter les propriétaires de sites web.
?️ Stockage flexible
Stockez les données structurées dans SQLite, les données non structurées dans un bucket compatible S3 et les données sémantiques dans une base de données vectorielle — le tout inclus avec votre crawler.
? Déploiement sans serveur
Déployez des web crawlers aussi facilement que vous déployez des sites web. Aucune infrastructure à gérer, aucun serveur à maintenir — concentrez-vous simplement sur la construction.
Cas d'utilisation
Collecte de données d'entraînement pour l'IA
Récoltez des données structurées et fraîches pour entraîner des modèles d'apprentissage automatique. Utilisez des LLM pour extraire et formater les données directement dans votre schéma préféré.Études de marché
Surveillez les sites web de vos concurrents, suivez les variations de prix ou récupérez les détails des produits à grande échelle, tout en respectant les limites de débit et robots.txt.Agrégation de contenu
Créez des ensembles de données dynamiques pour les agrégateurs d'actualités, les sites d'emploi ou les plateformes de recherche. Stockez les données dans des bases de données SQLite ou vectorielles pour une récupération et une analyse faciles.
Pourquoi choisir Crawlspace ?
Rentable : Explorez un million de pages pour seulement 5 $.
Convivial pour les développeurs : Priorité à TypeScript, avec prise en charge de JavaScript et des packages npm.
Observable : Surveillez les journaux de trafic à l'aide d'OpenTelemetry pour une transparence totale.
Égress toujours gratuit : Téléchargez vos ensembles de données sans vous soucier de coûts supplémentaires.
FAQ
Q : Comment Crawlspace réduit-il le trafic de robots redondant ?
A : Crawlspace utilise un cache TTL à l'échelle de la plateforme. Lorsque plusieurs crawlers demandent la même URL dans un intervalle de temps défini, la réponse est extraite du cache, réduisant ainsi le trafic vers le serveur d'origine.
Q : Puis-je explorer les sites web de médias sociaux ?
A : Non. Les plateformes de médias sociaux comme LinkedIn et X interdisent explicitement l'exploration dans leurs fichiers robots.txt. Pour les données des médias sociaux, envisagez d'utiliser des plateformes d'enrichissement de données.
Q : Puis-je utiliser des modèles d'IA tiers comme GPT-4 ?
A : Oui ! Placez vos jetons API dans le fichier .env de votre crawler et utilisez des modèles de fournisseurs tels qu'OpenAI ou Anthropic pour le scraping et l'intégration.
Q : Crawlspace est-il conforme aux politiques des sites web ?
A : Absolument. Crawlspace respecte robots.txt et la limitation du débit par défaut, garantissant que vos crawlers sont polis et conformes.
Construisez plus intelligemment, explorez mieux
Crawlspace est plus qu'une plateforme de web scraping ; c'est le fondement de votre prochaine idée révolutionnaire. Avec des prix abordables, des outils conviviaux pour les développeurs et un engagement envers une exploration respectueuse, c'est la solution ultime pour mettre à l'échelle vos efforts de collecte de données.
Prêt à commencer ? Déployez votre premier crawler dès aujourd'hui et découvrez l'avenir du web scraping.
More information on Crawlspace
Launched
2024-09
Pricing Model
Freemium
Starting Price
$29/ month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Gzip,OpenGraph
Crawlspace was manually vetted by our editorial team and was first featured on September 4th 2025.
Related Searches
Crawlspace Alternatives
Plus Alternatives-

L'outil ultime pour les développeurs en IA et les scientifiques des données, offrant une extraction de données Web efficace avec une gestion dynamique du contenu et une conversion Markdown.
-

Crawl4AI est un service d'exploration du Web puissant et gratuit conçu pour extraire des informations utiles des pages du Web et les rendre accessibles aux grands modèles de langage (LLM) et aux applications d'IA.
-

x-crawl est une bibliothèque d'exploration flexible Node.js assistée par l'IA. Son utilisation flexible et ses puissantes fonctions d'assistance IA rendent l'exploration plus efficace, plus intelligente et plus pratique.
-

Spider est un outil de crawling web haute performance, conçu pour la vitesse, l'évolutivité et l'accessibilité financière, idéal pour les projets d'IA et les modèles linguistiques de grande taille (LLM).
-

CrawlrLabs révolutionne la stratégie de tarification du e-commerce avec des fonctionnalités telles que la surveillance automatisée, des informations en temps réel et une intelligence personnalisable pour aider les entreprises à optimiser leurs prix et à rester compétitives.