
What is ModelBench?
ModelBench 是您构建、测试和部署 AI 解决方案的“一站式”平台,可显著加快开发速度。无论您是产品经理、提示词工程师还是开发者,ModelBench 都能赋能您的团队,让您轻松实验、比较和优化大型语言模型 (LLM),无需繁琐的编码。
为什么选择 ModelBench?
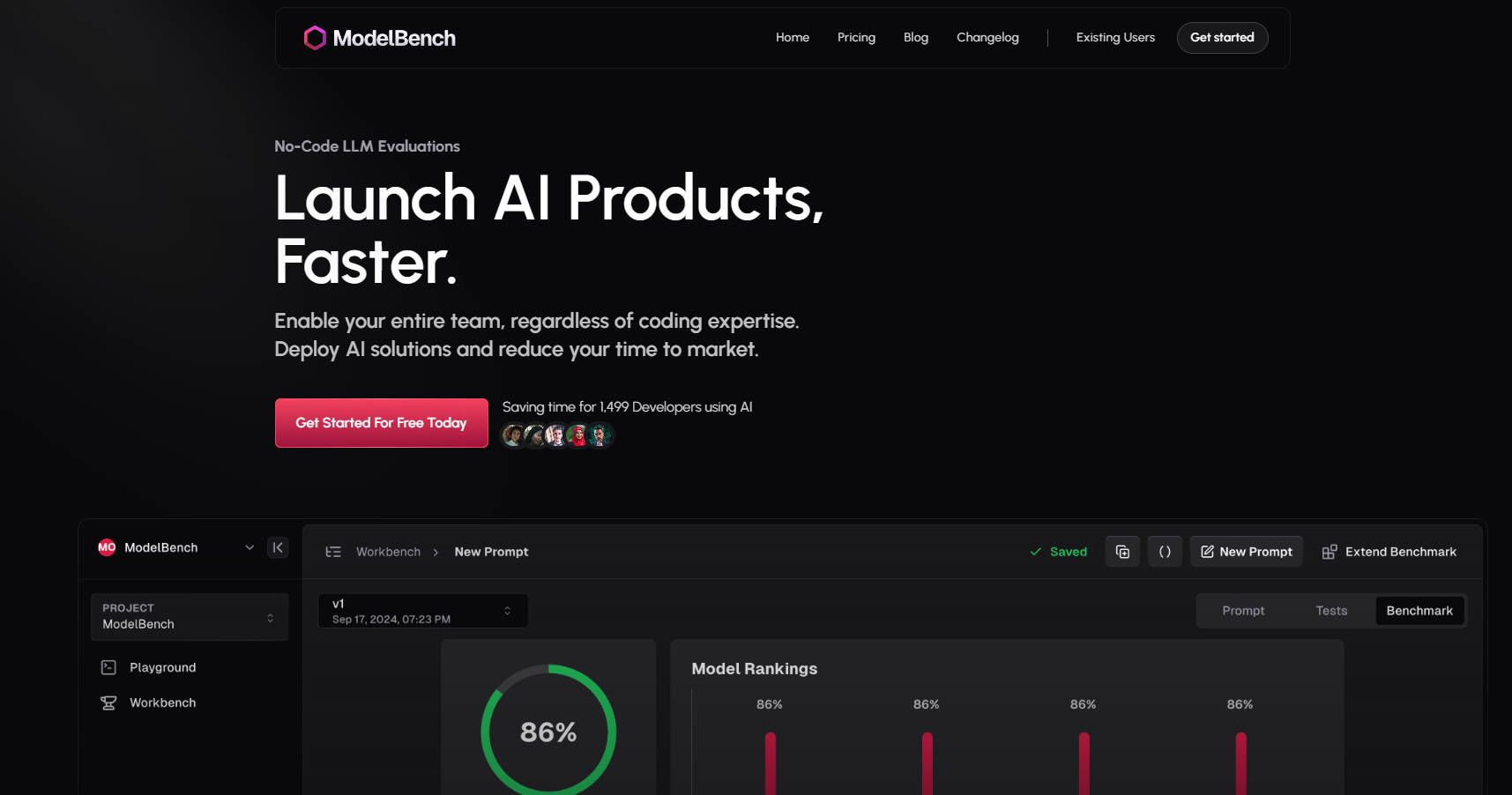
节省时间:并排比较 180 多个 LLM,在几分钟内即可找到性能最佳的模型和提示词。
无需代码的简易性:让您的整个团队都能参与实验和迭代,无论其技术专长如何。
更快的部署:大幅缩短开发和测试时间,缩短上市时间。
主要功能?
✅ 并排比较 180 多个模型
同时测试和评估多个 LLM,以找到最适合您用例的模型。
✅ 创建和微调提示词
设计、改进和测试提示词,并从多个模型获得即时反馈。
✅ 动态输入,实现可扩展的测试
从 Google Sheets 等工具导入数据集,并在无数场景中测试提示词。
✅ 与人类或 AI 进行基准测试
使用 AI、人工审核员或两者结合进行评估,以获得可靠的结果。
✅ 追踪和回放 LLM 运行
监控交互、回放响应并检测低质量输出,无需代码集成。
✅ 与您的团队协作
无缝共享提示词、结果和基准,从而加快开发速度。
ModelBench 的工作原理
Playground(实验场):
实时比较 180 多个模型。
轻松测试提示词并集成自定义工具。
Workbench(工作台):
将实验转化为结构化的基准测试。
使用动态输入和版本控制大规模测试提示词。
Benchmarking(基准测试):
对多个模型进行多轮测试。
分析结果以改进和优化您的提示词。
谁适合使用 ModelBench?
产品经理:快速验证 AI 解决方案并缩短上市时间。
提示词工程师:微调提示词并在多个模型中进行性能基准测试。
开发者:无需复杂的编码或框架即可体验 LLM。
用例
电子商务聊天机器人:测试和优化针对多个 LLM 的客户支持提示词。
内容生成:比较模型以找到最适合生成高质量、符合品牌形象内容的模型。
AI 驱动的工具:对 LLM 进行基准测试,以完成摘要、翻译或情感分析等任务。
立即开始
加入来自亚马逊、谷歌和 Twitch 等公司的 1499 位开发者和团队,一起使用 ModelBench 节省时间。
More information on ModelBench
Launched
2024-05
Pricing Model
Free Trial
Starting Price
49 $ Monthly
Global Rank
7049061
Follow
Month Visit
<5k
Tech used
Google Tag Manager,Amazon AWS CloudFront,Google Fonts
Top 5 Countries
86.44%
13.56%
United States
United Kingdom
Traffic Sources
71.7%
18.19%
4.93%
4.22%
0.93%
0.03%
Social
Direct
Search
Referrals
Paid Referrals
Mail
ModelBench was manually vetted by our editorial team and was first featured on 2025-01-21.
Related Searches
![[dangao]](/static/assets/comment/emotions/dangao.gif "[dangao]")
![[qiu]](/static/assets/comment/emotions/qiu.gif "[qiu]")
![[fadou]](/static/assets/comment/emotions/fadou.gif "[fadou]")
![[tiaopi]](/static/assets/comment/emotions/tiaopi.gif "[tiaopi]")
![[fadai]](/static/assets/comment/emotions/fadai.gif "[fadai]")
![[xinsui]](/static/assets/comment/emotions/xinsui.gif "[xinsui]")
![[ruo]](/static/assets/comment/emotions/ruo.gif "[ruo]")
![[jingkong]](/static/assets/comment/emotions/jingkong.gif "[jingkong]")
![[quantou]](/static/assets/comment/emotions/quantou.gif "[quantou]")
![[gangga]](/static/assets/comment/emotions/gangga.gif "[gangga]")
![[da]](/static/assets/comment/emotions/da.gif "[da]")
![[touxiao]](/static/assets/comment/emotions/touxiao.gif "[touxiao]")
![[ciya]](/static/assets/comment/emotions/ciya.gif "[ciya]")
![[liulei]](/static/assets/comment/emotions/liulei.gif "[liulei]")
![[fendou]](/static/assets/comment/emotions/fendou.gif "[fendou]")
![[kiss]](/static/assets/comment/emotions/kiss.gif "[kiss]")
![[aoman]](/static/assets/comment/emotions/aoman.gif "[aoman]")
![[kulou]](/static/assets/comment/emotions/kulou.gif "[kulou]")
![[yueliang]](/static/assets/comment/emotions/yueliang.gif "[yueliang]")
![[lenghan]](/static/assets/comment/emotions/lenghan.gif "[lenghan]")
![[kun]](/static/assets/comment/emotions/kun.gif "[kun]")
![[meng]](/static/assets/comment/emotions/meng.gif "[meng]")
![[shenma]](/static/assets/comment/emotions/shenma.gif "[shenma]")
![[peifu]](/static/assets/comment/emotions/peifu.gif "[peifu]")
![[qinqin]](/static/assets/comment/emotions/qinqin.gif "[qinqin]")
![[nanguo]](/static/assets/comment/emotions/nanguo.gif "[nanguo]")
![[hufen]](/static/assets/comment/emotions/hufen.gif "[hufen]")
![[shuai]](/static/assets/comment/emotions/shuai.gif "[shuai]")
![[jingya]](/static/assets/comment/emotions/jingya.gif "[jingya]")
![[cahan]](/static/assets/comment/emotions/cahan.gif "[cahan]")
![[shengli]](/static/assets/comment/emotions/shengli.gif "[shengli]")
![[qioudale]](/static/assets/comment/emotions/qioudale.gif "[qioudale]")
![[cheer]](/static/assets/comment/emotions/cheer.gif "[cheer]")
![[ketou]](/static/assets/comment/emotions/ketou.gif "[ketou]")
![[shandian]](/static/assets/comment/emotions/shandian.gif "[shandian]")
![[haqian]](/static/assets/comment/emotions/haqian.gif "[haqian]")
![[jidong]](/static/assets/comment/emotions/jidong.gif "[jidong]")
![[zaijian]](/static/assets/comment/emotions/zaijian.gif "[zaijian]")
![[kafei]](/static/assets/comment/emotions/kafei.gif "[kafei]")
![[love]](/static/assets/comment/emotions/love.gif "[love]")
![[pizui]](/static/assets/comment/emotions/pizui.gif "[pizui]")
![[huitou]](/static/assets/comment/emotions/huitou.gif "[huitou]")
![[tiao]](/static/assets/comment/emotions/tiao.gif "[tiao]")
![[liwu]](/static/assets/comment/emotions/liwu.gif "[liwu]")
![[zhutou]](/static/assets/comment/emotions/zhutou.gif "[zhutou]")
![[e]](/static/assets/comment/emotions/e.gif "[e]")
![[qiang]](/static/assets/comment/emotions/qiang.gif "[qiang]")
![[youtaiji]](/static/assets/comment/emotions/youtaiji.gif "[youtaiji]")
![[zuohengheng]](/static/assets/comment/emotions/zuohengheng.gif "[zuohengheng]")
![[huaixiao]](/static/assets/comment/emotions/huaixiao.gif "[huaixiao]")
![[gouyin]](/static/assets/comment/emotions/gouyin.gif "[gouyin]")
![[keai]](/static/assets/comment/emotions/keai.gif "[keai]")
![[tiaosheng]](/static/assets/comment/emotions/tiaosheng.gif "[tiaosheng]")
![[daku]](/static/assets/comment/emotions/daku.gif "[daku]")
![[weiqu]](/static/assets/comment/emotions/weiqu.gif "[weiqu]")
![[lanqiu]](/static/assets/comment/emotions/lanqiu.gif "[lanqiu]")
![[zhemo]](/static/assets/comment/emotions/zhemo.gif "[zhemo]")
![[xia]](/static/assets/comment/emotions/xia.gif "[xia]")
![[fan]](/static/assets/comment/emotions/fan.gif "[fan]")
![[yun]](/static/assets/comment/emotions/yun.gif "[yun]")
![[youhengheng]](/static/assets/comment/emotions/youhengheng.gif "[youhengheng]")
![[chong]](/static/assets/comment/emotions/chong.gif "[chong]")
![[pijiu]](/static/assets/comment/emotions/pijiu.gif "[pijiu]")
![[dajiao]](/static/assets/comment/emotions/dajiao.gif "[dajiao]")
![[dao]](/static/assets/comment/emotions/dao.gif "[dao]")
![[diaoxie]](/static/assets/comment/emotions/diaoxie.gif "[diaoxie]")
![[liuhan]](/static/assets/comment/emotions/liuhan.gif "[liuhan]")
![[haha]](/static/assets/comment/emotions/haha.gif "[haha]")
![[xu]](/static/assets/comment/emotions/xu.gif "[xu]")
![[zhuakuang]](/static/assets/comment/emotions/zhuakuang.gif "[zhuakuang]")
![[zhuanquan]](/static/assets/comment/emotions/zhuanquan.gif "[zhuanquan]")
![[no]](/static/assets/comment/emotions/no.gif "[no]")
![[ok]](/static/assets/comment/emotions/ok.gif "[ok]")
![[feiwen]](/static/assets/comment/emotions/feiwen.gif "[feiwen]")
![[taiyang]](/static/assets/comment/emotions/taiyang.gif "[taiyang]")
![[woshou]](/static/assets/comment/emotions/woshou.gif "[woshou]")
![[zuqiu]](/static/assets/comment/emotions/zuqiu.gif "[zuqiu]")
![[xigua]](/static/assets/comment/emotions/xigua.gif "[xigua]")
![[hua]](/static/assets/comment/emotions/hua.gif "[hua]")
![[tu]](/static/assets/comment/emotions/tu.gif "[tu]")
![[tiaowu]](/static/assets/comment/emotions/tiaowu.gif "[tiaowu]")
![[ma]](/static/assets/comment/emotions/ma.gif "[ma]")
![[baiyan]](/static/assets/comment/emotions/baiyan.gif "[baiyan]")
![[zhadan]](/static/assets/comment/emotions/zhadan.gif "[zhadan]")
![[weixiao]](/static/assets/comment/emotions/weixiao.gif "[weixiao]")
![[wen]](/static/assets/comment/emotions/wen.gif "[wen]")
![[dabing]](/static/assets/comment/emotions/dabing.gif "[dabing]")
![[xianwen]](/static/assets/comment/emotions/xianwen.gif "[xianwen]")
![[shuijiao]](/static/assets/comment/emotions/shuijiao.gif "[shuijiao]")
![[yongbao]](/static/assets/comment/emotions/yongbao.gif "[yongbao]")
![[kelian]](/static/assets/comment/emotions/kelian.gif "[kelian]")
![[pingpang]](/static/assets/comment/emotions/pingpang.gif "[pingpang]")
![[danu]](/static/assets/comment/emotions/danu.gif "[danu]")
![[geili]](/static/assets/comment/emotions/geili.gif "[geili]")
![[wabi]](/static/assets/comment/emotions/wabi.gif "[wabi]")
![[kuaikule]](/static/assets/comment/emotions/kuaikule.gif "[kuaikule]")
![[zuotaiji]](/static/assets/comment/emotions/zuotaiji.gif "[zuotaiji]")
![[tuzi]](/static/assets/comment/emotions/tuzi.gif "[tuzi]")
![[bishi]](/static/assets/comment/emotions/bishi.gif "[bishi]")
![[caidao]](/static/assets/comment/emotions/caidao.gif "[caidao]")
![[dabian]](/static/assets/comment/emotions/dabian.gif "[dabian]")
![[fanu]](/static/assets/comment/emotions/fanu.gif "[fanu]")
![[guzhang]](/static/assets/comment/emotions/guzhang.gif "[guzhang]")
![[se]](/static/assets/comment/emotions/se.gif "[se]")
![[chajin]](/static/assets/comment/emotions/chajin.gif "[chajin]")
![[bizui]](/static/assets/comment/emotions/bizui.gif "[bizui]")
![[deyi]](/static/assets/comment/emotions/deyi.gif "[deyi]")
![[ku]](/static/assets/comment/emotions/ku.gif "[ku]")
![[huishou]](/static/assets/comment/emotions/huishou.gif "[huishou]")
![[yinxian]](/static/assets/comment/emotions/yinxian.gif "[yinxian]")
![[haixiu]](/static/assets/comment/emotions/haixiu.gif "[haixiu]")
ModelBench 替代方案
更多 替代方案-

LiveBench 是一款 LLM 基准测试,每月从不同来源收集新的问题,并提供客观答案以进行准确评分。目前涵盖 6 个类别中的 18 个任务,并将不断增加更多任务。
-

-

WildBench 是一款先进的基准测试工具,用于评估大型语言模型 (LLM) 在各种现实世界任务中的表现。对于那些希望提高 AI 性能并了解模型在实际场景中的局限性的用户来说,它至关重要。
-

-
