
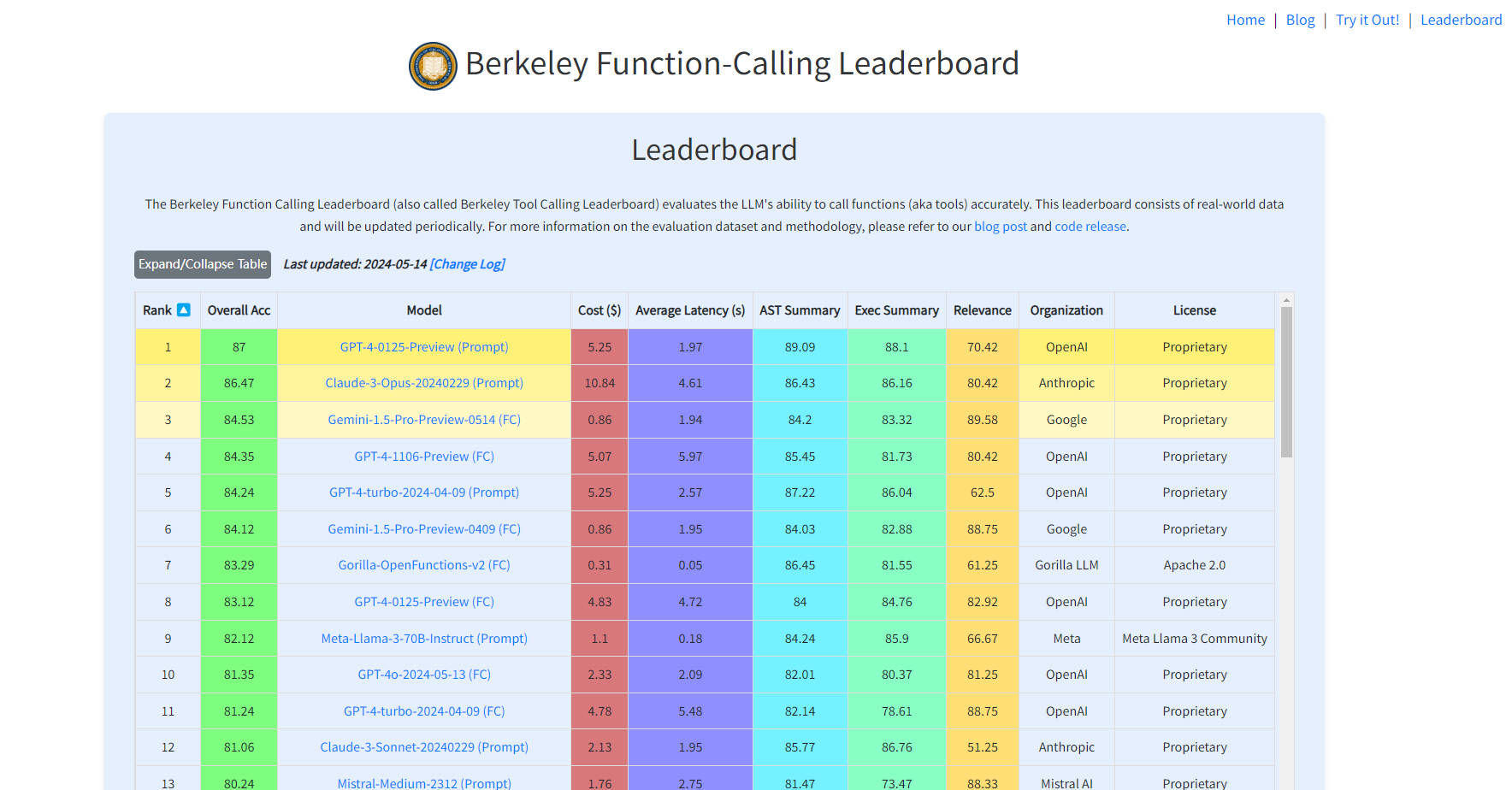
What is Berkeley Function-Calling Leaderboard?
Berkeley Function-Calling Leaderboard 是一個創新的線上平台,旨在評估大型語言模型 (LLM) 在準確呼叫函式或工具方面的能力。這個基於真實世界數據並定期更新的基準測試工具,為對 AI 程式設計能力感興趣的開發人員、研究人員和使用者提供了寶貴的資源。它使他們能夠比較和選擇最適合其特定需求的模型,評估經濟效率和效能。
主要功能
對 LLM 的全面評估:評估大型語言模型的函式呼叫能力。?
真實世界數據:利用實際數據集進行更準確和相關的評估。?
定期更新:讓排行榜始終保持最新,反映 AI 技術的最新進展。?
詳細的錯誤分析:提供對不同模型優缺點的洞察。?
模型比較:便於在模型之間進行輕鬆比較,以便做出明智的決策。?
成本和延遲估算:提供經濟和及時模型選擇的估算。?⏳
用例
研究比較:研究人員利用排行榜比較各種 LLM 在特定程式設計任務上的效能。
開發人員模型選擇:開發人員根據排行榜數據選擇最適合其應用的 AI 模型。
教育資源:教育機構使用該平台展示 AI 技術的最新進展。
使用方法
訪問網站:線上訪問 Berkeley Function-Calling Leaderboard。
查看排行榜:查看不同模型的當前得分和排名。
探索模型詳情:點擊模型以獲取詳細信息和評估數據。
分析錯誤類型:使用提供的工具了解模型在各種錯誤類型上的效能。
評估成本和延遲:參考成本和延遲估算以進行經濟和響應速度評估。
貢獻或提交:聯繫平台提交您自己的模型或貢獻測試用例。
結論
Berkeley Function-Calling Leaderboard 是 AI 社群中的一個重要工具,它提供了一種透明且數據驅動的方法來評估和選擇最有效的程式設計任務大型語言模型。通過提供全面的評估、真實世界的洞察力和實用的比較,它使使用者能夠做出明智的決策,從而提高 AI 應用的效率和有效性。加入前瞻性專業人士的行列,探索 AI 程式設計的潛力,使用 Berkeley Function-Calling Leaderboard。
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on September 4th 2025.
Related Searches
![[dangao]](/static/assets/comment/emotions/dangao.gif "[dangao]")
![[qiu]](/static/assets/comment/emotions/qiu.gif "[qiu]")
![[fadou]](/static/assets/comment/emotions/fadou.gif "[fadou]")
![[tiaopi]](/static/assets/comment/emotions/tiaopi.gif "[tiaopi]")
![[fadai]](/static/assets/comment/emotions/fadai.gif "[fadai]")
![[xinsui]](/static/assets/comment/emotions/xinsui.gif "[xinsui]")
![[ruo]](/static/assets/comment/emotions/ruo.gif "[ruo]")
![[jingkong]](/static/assets/comment/emotions/jingkong.gif "[jingkong]")
![[quantou]](/static/assets/comment/emotions/quantou.gif "[quantou]")
![[gangga]](/static/assets/comment/emotions/gangga.gif "[gangga]")
![[da]](/static/assets/comment/emotions/da.gif "[da]")
![[touxiao]](/static/assets/comment/emotions/touxiao.gif "[touxiao]")
![[ciya]](/static/assets/comment/emotions/ciya.gif "[ciya]")
![[liulei]](/static/assets/comment/emotions/liulei.gif "[liulei]")
![[fendou]](/static/assets/comment/emotions/fendou.gif "[fendou]")
![[kiss]](/static/assets/comment/emotions/kiss.gif "[kiss]")
![[aoman]](/static/assets/comment/emotions/aoman.gif "[aoman]")
![[kulou]](/static/assets/comment/emotions/kulou.gif "[kulou]")
![[yueliang]](/static/assets/comment/emotions/yueliang.gif "[yueliang]")
![[lenghan]](/static/assets/comment/emotions/lenghan.gif "[lenghan]")
![[kun]](/static/assets/comment/emotions/kun.gif "[kun]")
![[meng]](/static/assets/comment/emotions/meng.gif "[meng]")
![[shenma]](/static/assets/comment/emotions/shenma.gif "[shenma]")
![[peifu]](/static/assets/comment/emotions/peifu.gif "[peifu]")
![[qinqin]](/static/assets/comment/emotions/qinqin.gif "[qinqin]")
![[nanguo]](/static/assets/comment/emotions/nanguo.gif "[nanguo]")
![[hufen]](/static/assets/comment/emotions/hufen.gif "[hufen]")
![[shuai]](/static/assets/comment/emotions/shuai.gif "[shuai]")
![[jingya]](/static/assets/comment/emotions/jingya.gif "[jingya]")
![[cahan]](/static/assets/comment/emotions/cahan.gif "[cahan]")
![[shengli]](/static/assets/comment/emotions/shengli.gif "[shengli]")
![[qioudale]](/static/assets/comment/emotions/qioudale.gif "[qioudale]")
![[cheer]](/static/assets/comment/emotions/cheer.gif "[cheer]")
![[ketou]](/static/assets/comment/emotions/ketou.gif "[ketou]")
![[shandian]](/static/assets/comment/emotions/shandian.gif "[shandian]")
![[haqian]](/static/assets/comment/emotions/haqian.gif "[haqian]")
![[jidong]](/static/assets/comment/emotions/jidong.gif "[jidong]")
![[zaijian]](/static/assets/comment/emotions/zaijian.gif "[zaijian]")
![[kafei]](/static/assets/comment/emotions/kafei.gif "[kafei]")
![[love]](/static/assets/comment/emotions/love.gif "[love]")
![[pizui]](/static/assets/comment/emotions/pizui.gif "[pizui]")
![[huitou]](/static/assets/comment/emotions/huitou.gif "[huitou]")
![[tiao]](/static/assets/comment/emotions/tiao.gif "[tiao]")
![[liwu]](/static/assets/comment/emotions/liwu.gif "[liwu]")
![[zhutou]](/static/assets/comment/emotions/zhutou.gif "[zhutou]")
![[e]](/static/assets/comment/emotions/e.gif "[e]")
![[qiang]](/static/assets/comment/emotions/qiang.gif "[qiang]")
![[youtaiji]](/static/assets/comment/emotions/youtaiji.gif "[youtaiji]")
![[zuohengheng]](/static/assets/comment/emotions/zuohengheng.gif "[zuohengheng]")
![[huaixiao]](/static/assets/comment/emotions/huaixiao.gif "[huaixiao]")
![[gouyin]](/static/assets/comment/emotions/gouyin.gif "[gouyin]")
![[keai]](/static/assets/comment/emotions/keai.gif "[keai]")
![[tiaosheng]](/static/assets/comment/emotions/tiaosheng.gif "[tiaosheng]")
![[daku]](/static/assets/comment/emotions/daku.gif "[daku]")
![[weiqu]](/static/assets/comment/emotions/weiqu.gif "[weiqu]")
![[lanqiu]](/static/assets/comment/emotions/lanqiu.gif "[lanqiu]")
![[zhemo]](/static/assets/comment/emotions/zhemo.gif "[zhemo]")
![[xia]](/static/assets/comment/emotions/xia.gif "[xia]")
![[fan]](/static/assets/comment/emotions/fan.gif "[fan]")
![[yun]](/static/assets/comment/emotions/yun.gif "[yun]")
![[youhengheng]](/static/assets/comment/emotions/youhengheng.gif "[youhengheng]")
![[chong]](/static/assets/comment/emotions/chong.gif "[chong]")
![[pijiu]](/static/assets/comment/emotions/pijiu.gif "[pijiu]")
![[dajiao]](/static/assets/comment/emotions/dajiao.gif "[dajiao]")
![[dao]](/static/assets/comment/emotions/dao.gif "[dao]")
![[diaoxie]](/static/assets/comment/emotions/diaoxie.gif "[diaoxie]")
![[liuhan]](/static/assets/comment/emotions/liuhan.gif "[liuhan]")
![[haha]](/static/assets/comment/emotions/haha.gif "[haha]")
![[xu]](/static/assets/comment/emotions/xu.gif "[xu]")
![[zhuakuang]](/static/assets/comment/emotions/zhuakuang.gif "[zhuakuang]")
![[zhuanquan]](/static/assets/comment/emotions/zhuanquan.gif "[zhuanquan]")
![[no]](/static/assets/comment/emotions/no.gif "[no]")
![[ok]](/static/assets/comment/emotions/ok.gif "[ok]")
![[feiwen]](/static/assets/comment/emotions/feiwen.gif "[feiwen]")
![[taiyang]](/static/assets/comment/emotions/taiyang.gif "[taiyang]")
![[woshou]](/static/assets/comment/emotions/woshou.gif "[woshou]")
![[zuqiu]](/static/assets/comment/emotions/zuqiu.gif "[zuqiu]")
![[xigua]](/static/assets/comment/emotions/xigua.gif "[xigua]")
![[hua]](/static/assets/comment/emotions/hua.gif "[hua]")
![[tu]](/static/assets/comment/emotions/tu.gif "[tu]")
![[tiaowu]](/static/assets/comment/emotions/tiaowu.gif "[tiaowu]")
![[ma]](/static/assets/comment/emotions/ma.gif "[ma]")
![[baiyan]](/static/assets/comment/emotions/baiyan.gif "[baiyan]")
![[zhadan]](/static/assets/comment/emotions/zhadan.gif "[zhadan]")
![[weixiao]](/static/assets/comment/emotions/weixiao.gif "[weixiao]")
![[wen]](/static/assets/comment/emotions/wen.gif "[wen]")
![[dabing]](/static/assets/comment/emotions/dabing.gif "[dabing]")
![[xianwen]](/static/assets/comment/emotions/xianwen.gif "[xianwen]")
![[shuijiao]](/static/assets/comment/emotions/shuijiao.gif "[shuijiao]")
![[yongbao]](/static/assets/comment/emotions/yongbao.gif "[yongbao]")
![[kelian]](/static/assets/comment/emotions/kelian.gif "[kelian]")
![[pingpang]](/static/assets/comment/emotions/pingpang.gif "[pingpang]")
![[danu]](/static/assets/comment/emotions/danu.gif "[danu]")
![[geili]](/static/assets/comment/emotions/geili.gif "[geili]")
![[wabi]](/static/assets/comment/emotions/wabi.gif "[wabi]")
![[kuaikule]](/static/assets/comment/emotions/kuaikule.gif "[kuaikule]")
![[zuotaiji]](/static/assets/comment/emotions/zuotaiji.gif "[zuotaiji]")
![[tuzi]](/static/assets/comment/emotions/tuzi.gif "[tuzi]")
![[bishi]](/static/assets/comment/emotions/bishi.gif "[bishi]")
![[caidao]](/static/assets/comment/emotions/caidao.gif "[caidao]")
![[dabian]](/static/assets/comment/emotions/dabian.gif "[dabian]")
![[fanu]](/static/assets/comment/emotions/fanu.gif "[fanu]")
![[guzhang]](/static/assets/comment/emotions/guzhang.gif "[guzhang]")
![[se]](/static/assets/comment/emotions/se.gif "[se]")
![[chajin]](/static/assets/comment/emotions/chajin.gif "[chajin]")
![[bizui]](/static/assets/comment/emotions/bizui.gif "[bizui]")
![[deyi]](/static/assets/comment/emotions/deyi.gif "[deyi]")
![[ku]](/static/assets/comment/emotions/ku.gif "[ku]")
![[huishou]](/static/assets/comment/emotions/huishou.gif "[huishou]")
![[yinxian]](/static/assets/comment/emotions/yinxian.gif "[yinxian]")
![[haixiu]](/static/assets/comment/emotions/haixiu.gif "[haixiu]")
Berkeley Function-Calling Leaderboard 替代方案
更多 替代方案-

Huggingface 的 Open LLM Leaderboard 目標是促進語言模型評估的開放合作與透明度。
-

即時的 Klu.ai 資料為此排行榜提供動力,用於評估 LLM 供應商,讓您能夠根據自身需求選擇最佳的 API 和模型。
-
透過 Agent Leaderboard 選擇最符合您需求的 AI 代理程式——此排行榜提供橫跨 14 項基準的公正、真實效能見解。
-

LiveBench 是一個大型語言模型基準測試,每月從不同來源獲得新問題和客觀答案,以進行準確評分。目前包含 6 個類別的 18 個任務,並將陸續增加更多任務。
-

SEAL 排行榜顯示,OpenAI 的 GPT 系列大型語言模型 (LLM) 在用於評估 AI 模型的四個初始領域中的三個領域中排名第一,Anthropic PBC 的熱門 Claude 3 Opus 在第四個類別中奪得第一。Google LLC 的 Gemini 模型也表現出色,在幾個領域中與 GPT 模型並列第一。