
What is cocoindex?
打造如 Retrieval-Augmented Generation (RAG) 系統這樣強大的 AI 應用程式,需要高品質、容易取得且隨時保持最新的資料。然而,建構和維護必要的資料管線——從各種來源擷取資料、轉換複雜的資訊,以及有效地建立索引——通常是一項複雜、容易出錯且耗時的挑戰。讓這些已建立索引的資料與不斷變化的來源保持同步,更增加了另一層難度。
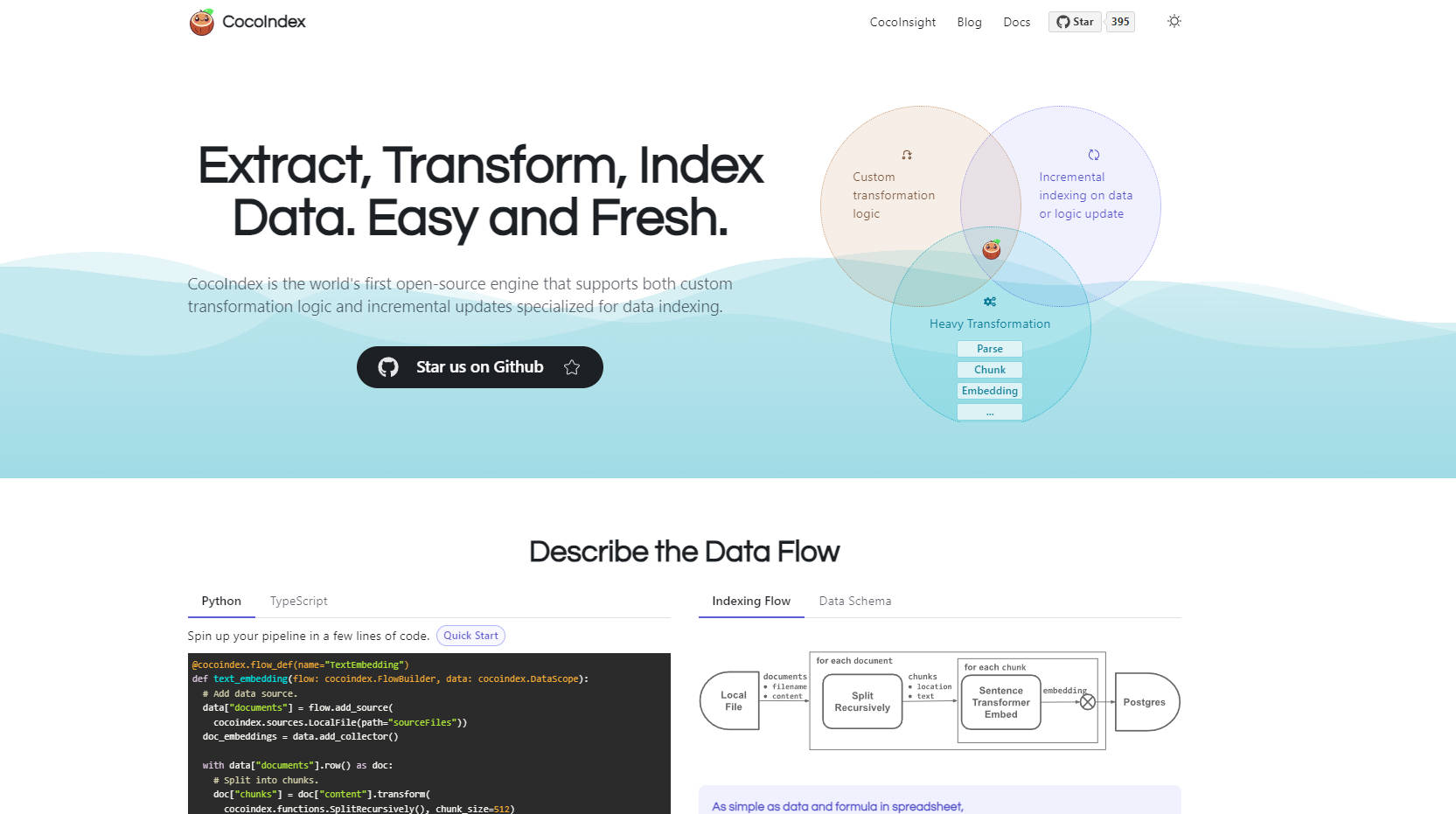
CocoIndex 的出現,就是為了簡化整個流程的一個開源框架。它提供了一種強大且宣告式的方法,來定義 AI 的資料索引管線,獨特地結合了對自訂轉換邏輯和即時增量更新的支援。您可以將其視為像試算表公式一樣定義您的資料流——您宣告資料來源和轉換,而 CocoIndex 則處理複雜的執行,確保您的 AI 應用程式始終使用最新鮮的資訊。
主要功能:
⚙️ 定義自訂 ETL 邏輯: 使用基於 Python 的彈性定義,輕鬆實現您特定的資料處理需求——解析各種檔案類型(PDF、HTML、Docs)、使用不同的策略對文本進行分塊、使用您選擇的模型生成嵌入、提取知識圖譜三元組等等。
🔄 自動化增量更新: CocoIndex 自動監控您的資料來源和轉換邏輯。當發生變更時,它會智慧地重新處理必要的區塊,盡可能重複使用快取,並清除過時的資料,確保您的索引始終保持最新,且延遲時間短。
🏗️ 簡化管線管理: 忘掉手動架構設定、複雜的重新處理邏輯或恢復失敗的工作。CocoIndex 處理繁重的運營工作:管理表格架構、追蹤資料/邏輯版本、確保資料新鮮度,以及實現從中斷中強大的恢復。
📊 利用內建的可觀察性: 確切了解您的資料如何流動和轉換。透過整合的沿襲追蹤和用於視覺化的工具(例如,用於比較分塊策略的 CocoInsight),您可以清楚地進行除錯、最佳化和信任您的資料管線。
🚀 無縫擴展: 定義一次您的管線,並在不同的情境中執行它。CocoIndex 支援用於開發的快速預覽執行、用於初始索引的大規模批次處理,以及用於生產環境的連續低延遲更新。
🔌 連接多樣化的生態系統: 輕鬆地與各種資料來源(網頁、文件、資料庫、雲端儲存、API)和目標索引儲存(Vector Stores、Graph Stores、Relational Stores、Object Stores)整合。
CocoIndex 如何為您服務:使用案例
為動態 RAG 系統提供動力: 想像一下,建構一個 RAG 應用程式,根據您公司不斷更新的內部文件來回答問題。透過 CocoIndex,您可以定義一次管線,以擷取文件、適當地對其進行分塊、生成嵌入,並將其儲存在向量資料庫中。當新增或修改文件時,CocoIndex 會自動以增量方式更新索引,確保您的 RAG 系統始終根據最新的資訊提供答案,而無需手動干預或完全重新建立索引。
建立複雜的語義搜尋: 您需要跨多個資料孤島啟用語義搜尋——產品手冊(PDF)、支援票證(資料庫)和行銷內容(網頁)。CocoIndex 允許您為每個來源定義不同的擷取和轉換步驟,可能使用不同的分塊或嵌入策略,並將結果整合到統一的向量索引中。它的增量更新使搜尋每天都保持相關性。
建構知識圖譜增強的 AI: 對於需要結構化知識的 AI 代理程式,您可以使用 CocoIndex 從非結構化文字文件中提取實體和關係,將它們轉換為三元組,並將它們載入到圖形資料庫中,同時將向量嵌入儲存在另一個儲存中。CocoIndex 管理依賴關係,並在來源文件變更時更新兩個索引。
CocoIndex 為一個關鍵的 AI 基礎架構挑戰提供了一個重點解決方案:準備和維護新鮮、高品質的資料索引。透過結合開發人員友好的宣告式方法、強大的自訂轉換能力和自動化的增量更新,它顯著降低了為 RAG、語義搜尋和其他 AI 應用程式建構強大資料管線的複雜性和運營負擔。它的開源性質和不斷增長的生態系統使其成為您的 AI 專案一個易於存取和適應的基礎。
More information on cocoindex
Launched
2024-12
Pricing Model
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Fastly,Next.js,GitHub Pages,Gzip,Varnish,Webpack
cocoindex was manually vetted by our editorial team and was first featured on September 4th 2025.
![[dangao]](/static/assets/comment/emotions/dangao.gif "[dangao]")
![[qiu]](/static/assets/comment/emotions/qiu.gif "[qiu]")
![[fadou]](/static/assets/comment/emotions/fadou.gif "[fadou]")
![[tiaopi]](/static/assets/comment/emotions/tiaopi.gif "[tiaopi]")
![[fadai]](/static/assets/comment/emotions/fadai.gif "[fadai]")
![[xinsui]](/static/assets/comment/emotions/xinsui.gif "[xinsui]")
![[ruo]](/static/assets/comment/emotions/ruo.gif "[ruo]")
![[jingkong]](/static/assets/comment/emotions/jingkong.gif "[jingkong]")
![[quantou]](/static/assets/comment/emotions/quantou.gif "[quantou]")
![[gangga]](/static/assets/comment/emotions/gangga.gif "[gangga]")
![[da]](/static/assets/comment/emotions/da.gif "[da]")
![[touxiao]](/static/assets/comment/emotions/touxiao.gif "[touxiao]")
![[ciya]](/static/assets/comment/emotions/ciya.gif "[ciya]")
![[liulei]](/static/assets/comment/emotions/liulei.gif "[liulei]")
![[fendou]](/static/assets/comment/emotions/fendou.gif "[fendou]")
![[kiss]](/static/assets/comment/emotions/kiss.gif "[kiss]")
![[aoman]](/static/assets/comment/emotions/aoman.gif "[aoman]")
![[kulou]](/static/assets/comment/emotions/kulou.gif "[kulou]")
![[yueliang]](/static/assets/comment/emotions/yueliang.gif "[yueliang]")
![[lenghan]](/static/assets/comment/emotions/lenghan.gif "[lenghan]")
![[kun]](/static/assets/comment/emotions/kun.gif "[kun]")
![[meng]](/static/assets/comment/emotions/meng.gif "[meng]")
![[shenma]](/static/assets/comment/emotions/shenma.gif "[shenma]")
![[peifu]](/static/assets/comment/emotions/peifu.gif "[peifu]")
![[qinqin]](/static/assets/comment/emotions/qinqin.gif "[qinqin]")
![[nanguo]](/static/assets/comment/emotions/nanguo.gif "[nanguo]")
![[hufen]](/static/assets/comment/emotions/hufen.gif "[hufen]")
![[shuai]](/static/assets/comment/emotions/shuai.gif "[shuai]")
![[jingya]](/static/assets/comment/emotions/jingya.gif "[jingya]")
![[cahan]](/static/assets/comment/emotions/cahan.gif "[cahan]")
![[shengli]](/static/assets/comment/emotions/shengli.gif "[shengli]")
![[qioudale]](/static/assets/comment/emotions/qioudale.gif "[qioudale]")
![[cheer]](/static/assets/comment/emotions/cheer.gif "[cheer]")
![[ketou]](/static/assets/comment/emotions/ketou.gif "[ketou]")
![[shandian]](/static/assets/comment/emotions/shandian.gif "[shandian]")
![[haqian]](/static/assets/comment/emotions/haqian.gif "[haqian]")
![[jidong]](/static/assets/comment/emotions/jidong.gif "[jidong]")
![[zaijian]](/static/assets/comment/emotions/zaijian.gif "[zaijian]")
![[kafei]](/static/assets/comment/emotions/kafei.gif "[kafei]")
![[love]](/static/assets/comment/emotions/love.gif "[love]")
![[pizui]](/static/assets/comment/emotions/pizui.gif "[pizui]")
![[huitou]](/static/assets/comment/emotions/huitou.gif "[huitou]")
![[tiao]](/static/assets/comment/emotions/tiao.gif "[tiao]")
![[liwu]](/static/assets/comment/emotions/liwu.gif "[liwu]")
![[zhutou]](/static/assets/comment/emotions/zhutou.gif "[zhutou]")
![[e]](/static/assets/comment/emotions/e.gif "[e]")
![[qiang]](/static/assets/comment/emotions/qiang.gif "[qiang]")
![[youtaiji]](/static/assets/comment/emotions/youtaiji.gif "[youtaiji]")
![[zuohengheng]](/static/assets/comment/emotions/zuohengheng.gif "[zuohengheng]")
![[huaixiao]](/static/assets/comment/emotions/huaixiao.gif "[huaixiao]")
![[gouyin]](/static/assets/comment/emotions/gouyin.gif "[gouyin]")
![[keai]](/static/assets/comment/emotions/keai.gif "[keai]")
![[tiaosheng]](/static/assets/comment/emotions/tiaosheng.gif "[tiaosheng]")
![[daku]](/static/assets/comment/emotions/daku.gif "[daku]")
![[weiqu]](/static/assets/comment/emotions/weiqu.gif "[weiqu]")
![[lanqiu]](/static/assets/comment/emotions/lanqiu.gif "[lanqiu]")
![[zhemo]](/static/assets/comment/emotions/zhemo.gif "[zhemo]")
![[xia]](/static/assets/comment/emotions/xia.gif "[xia]")
![[fan]](/static/assets/comment/emotions/fan.gif "[fan]")
![[yun]](/static/assets/comment/emotions/yun.gif "[yun]")
![[youhengheng]](/static/assets/comment/emotions/youhengheng.gif "[youhengheng]")
![[chong]](/static/assets/comment/emotions/chong.gif "[chong]")
![[pijiu]](/static/assets/comment/emotions/pijiu.gif "[pijiu]")
![[dajiao]](/static/assets/comment/emotions/dajiao.gif "[dajiao]")
![[dao]](/static/assets/comment/emotions/dao.gif "[dao]")
![[diaoxie]](/static/assets/comment/emotions/diaoxie.gif "[diaoxie]")
![[liuhan]](/static/assets/comment/emotions/liuhan.gif "[liuhan]")
![[haha]](/static/assets/comment/emotions/haha.gif "[haha]")
![[xu]](/static/assets/comment/emotions/xu.gif "[xu]")
![[zhuakuang]](/static/assets/comment/emotions/zhuakuang.gif "[zhuakuang]")
![[zhuanquan]](/static/assets/comment/emotions/zhuanquan.gif "[zhuanquan]")
![[no]](/static/assets/comment/emotions/no.gif "[no]")
![[ok]](/static/assets/comment/emotions/ok.gif "[ok]")
![[feiwen]](/static/assets/comment/emotions/feiwen.gif "[feiwen]")
![[taiyang]](/static/assets/comment/emotions/taiyang.gif "[taiyang]")
![[woshou]](/static/assets/comment/emotions/woshou.gif "[woshou]")
![[zuqiu]](/static/assets/comment/emotions/zuqiu.gif "[zuqiu]")
![[xigua]](/static/assets/comment/emotions/xigua.gif "[xigua]")
![[hua]](/static/assets/comment/emotions/hua.gif "[hua]")
![[tu]](/static/assets/comment/emotions/tu.gif "[tu]")
![[tiaowu]](/static/assets/comment/emotions/tiaowu.gif "[tiaowu]")
![[ma]](/static/assets/comment/emotions/ma.gif "[ma]")
![[baiyan]](/static/assets/comment/emotions/baiyan.gif "[baiyan]")
![[zhadan]](/static/assets/comment/emotions/zhadan.gif "[zhadan]")
![[weixiao]](/static/assets/comment/emotions/weixiao.gif "[weixiao]")
![[wen]](/static/assets/comment/emotions/wen.gif "[wen]")
![[dabing]](/static/assets/comment/emotions/dabing.gif "[dabing]")
![[xianwen]](/static/assets/comment/emotions/xianwen.gif "[xianwen]")
![[shuijiao]](/static/assets/comment/emotions/shuijiao.gif "[shuijiao]")
![[yongbao]](/static/assets/comment/emotions/yongbao.gif "[yongbao]")
![[kelian]](/static/assets/comment/emotions/kelian.gif "[kelian]")
![[pingpang]](/static/assets/comment/emotions/pingpang.gif "[pingpang]")
![[danu]](/static/assets/comment/emotions/danu.gif "[danu]")
![[geili]](/static/assets/comment/emotions/geili.gif "[geili]")
![[wabi]](/static/assets/comment/emotions/wabi.gif "[wabi]")
![[kuaikule]](/static/assets/comment/emotions/kuaikule.gif "[kuaikule]")
![[zuotaiji]](/static/assets/comment/emotions/zuotaiji.gif "[zuotaiji]")
![[tuzi]](/static/assets/comment/emotions/tuzi.gif "[tuzi]")
![[bishi]](/static/assets/comment/emotions/bishi.gif "[bishi]")
![[caidao]](/static/assets/comment/emotions/caidao.gif "[caidao]")
![[dabian]](/static/assets/comment/emotions/dabian.gif "[dabian]")
![[fanu]](/static/assets/comment/emotions/fanu.gif "[fanu]")
![[guzhang]](/static/assets/comment/emotions/guzhang.gif "[guzhang]")
![[se]](/static/assets/comment/emotions/se.gif "[se]")
![[chajin]](/static/assets/comment/emotions/chajin.gif "[chajin]")
![[bizui]](/static/assets/comment/emotions/bizui.gif "[bizui]")
![[deyi]](/static/assets/comment/emotions/deyi.gif "[deyi]")
![[ku]](/static/assets/comment/emotions/ku.gif "[ku]")
![[huishou]](/static/assets/comment/emotions/huishou.gif "[huishou]")
![[yinxian]](/static/assets/comment/emotions/yinxian.gif "[yinxian]")
![[haixiu]](/static/assets/comment/emotions/haixiu.gif "[haixiu]")
cocoindex 替代方案
更多 替代方案-

-

在幾分鐘內將外部資料連接到 AI 應用程式! 使用最快速的方式連結 LLM 的檢索引擎。透過一個 API 呼叫,連接任何資料,如網站、檔案。內建的提取、處理和同步功能。統一搜尋,零設定向量資料庫。價格合理,沒有額外加價。加入候補名單以搶先體驗。
-

-

-

Carbon 是一個以開發者為中心的平台,能將外部數據連接到大型語言模型 (LLM),讓 AI 能夠存取並運用自訂數據來源,以產生客製化的回應。