
What is CogVLM & CogAgent?
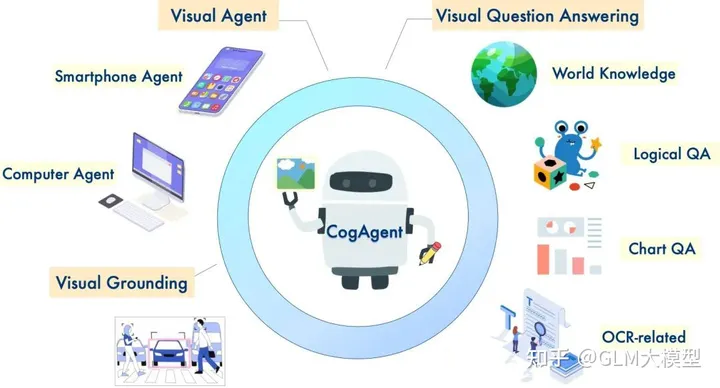
CogVLM и CogAgent — это мощные языковые модели с открытым исходным кодом, которые отлично подходят для понимания изображений и многоходового диалога. CogVLM-17B достигает передовых результатов в различных кросс-модальных тестах, демонстрируя свои надежные возможности в создании подписей к изображениям, ответе на визуальные вопросы и заземлении задач. Улучшенная версия CogAgent-18B еще больше расширяет эти возможности и представляет собой функциональность GUI Agent, позволяющую взаимодействовать с изображениями высокого разрешения и выполнять задачи с помощью скриншотов GUI.
Ключевые особенности:
1️⃣ Понимание изображений и диалог (CogVLM-17B):
?️ Обрабатывает понимание изображений и генерирует подробные описания.
? Участвует в многоходовых диалогах с визуальным контекстом.
2️⃣ GUI-агент и расширенные возможности (CogAgent-18B):
?️ Поддерживает входные изображения с высоким разрешением (1120x1120) для лучшего визуального восприятия.
?? Обладает возможностями GUI-агента, выполняя задачи и отвечая на вопросы, связанные со скриншотами GUI.
? Демонстрирует улучшенные возможности, связанные с OCR, благодаря специализированному обучению.
3️⃣ Заземление и несколько режимов диалога:
? Предоставляет описания изображений с координатами ограничивающего прямоугольника для объектов.
? Получает координаты ограничивающего прямоугольника на основе описаний объекта.
? Генерирует описания из указанных координат ограничивающего прямоугольника.
Варианты использования:
? Визуальное рассуждение на естественном языке:CogVLM и CogAgent отлично справляются с задачами, требующими визуального восприятия и генерации языка, такими как создание подписей к изображениям, ответ на визуальные вопросы и заземление задач.
? Взаимодействие и автоматизация GUI:Возможности GUI Agent у CogAgent делают его подходящим для задач, связанных со взаимодействием со скриншотами GUI, такими как веб-страницы, приложения и программное обеспечение.
? Ответы на вопросы с визуальным контекстом:Обе модели могут отвечать на вопросы, связанные с изображениями, предоставляя информативные ответы, основанные на понимании визуального контекста.
? Генерация языка с визуальным вводом:На основе изображения CogVLM и CogAgent могут генерировать подробные описания, истории или диалоги, которые согласуются с визуальным содержанием.
Заключение:
CogVLM и CogAgent — это универсальные языковые модели, которые сочетают в себе понимание изображений, многоходовой диалог и функциональность GUI Agent. Их мощные возможности делают их ценными активами для различных приложений, включая визуальное рассуждение на основе естественного языка, взаимодействие и автоматизацию GUI, ответы на вопросы с визуальным контекстом и генерацию языка с визуальным вводом.
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on September 4th 2025.
Related Searches
![[dangao]](/static/assets/comment/emotions/dangao.gif "[dangao]")
![[qiu]](/static/assets/comment/emotions/qiu.gif "[qiu]")
![[fadou]](/static/assets/comment/emotions/fadou.gif "[fadou]")
![[tiaopi]](/static/assets/comment/emotions/tiaopi.gif "[tiaopi]")
![[fadai]](/static/assets/comment/emotions/fadai.gif "[fadai]")
![[xinsui]](/static/assets/comment/emotions/xinsui.gif "[xinsui]")
![[ruo]](/static/assets/comment/emotions/ruo.gif "[ruo]")
![[jingkong]](/static/assets/comment/emotions/jingkong.gif "[jingkong]")
![[quantou]](/static/assets/comment/emotions/quantou.gif "[quantou]")
![[gangga]](/static/assets/comment/emotions/gangga.gif "[gangga]")
![[da]](/static/assets/comment/emotions/da.gif "[da]")
![[touxiao]](/static/assets/comment/emotions/touxiao.gif "[touxiao]")
![[ciya]](/static/assets/comment/emotions/ciya.gif "[ciya]")
![[liulei]](/static/assets/comment/emotions/liulei.gif "[liulei]")
![[fendou]](/static/assets/comment/emotions/fendou.gif "[fendou]")
![[kiss]](/static/assets/comment/emotions/kiss.gif "[kiss]")
![[aoman]](/static/assets/comment/emotions/aoman.gif "[aoman]")
![[kulou]](/static/assets/comment/emotions/kulou.gif "[kulou]")
![[yueliang]](/static/assets/comment/emotions/yueliang.gif "[yueliang]")
![[lenghan]](/static/assets/comment/emotions/lenghan.gif "[lenghan]")
![[kun]](/static/assets/comment/emotions/kun.gif "[kun]")
![[meng]](/static/assets/comment/emotions/meng.gif "[meng]")
![[shenma]](/static/assets/comment/emotions/shenma.gif "[shenma]")
![[peifu]](/static/assets/comment/emotions/peifu.gif "[peifu]")
![[qinqin]](/static/assets/comment/emotions/qinqin.gif "[qinqin]")
![[nanguo]](/static/assets/comment/emotions/nanguo.gif "[nanguo]")
![[hufen]](/static/assets/comment/emotions/hufen.gif "[hufen]")
![[shuai]](/static/assets/comment/emotions/shuai.gif "[shuai]")
![[jingya]](/static/assets/comment/emotions/jingya.gif "[jingya]")
![[cahan]](/static/assets/comment/emotions/cahan.gif "[cahan]")
![[shengli]](/static/assets/comment/emotions/shengli.gif "[shengli]")
![[qioudale]](/static/assets/comment/emotions/qioudale.gif "[qioudale]")
![[cheer]](/static/assets/comment/emotions/cheer.gif "[cheer]")
![[ketou]](/static/assets/comment/emotions/ketou.gif "[ketou]")
![[shandian]](/static/assets/comment/emotions/shandian.gif "[shandian]")
![[haqian]](/static/assets/comment/emotions/haqian.gif "[haqian]")
![[jidong]](/static/assets/comment/emotions/jidong.gif "[jidong]")
![[zaijian]](/static/assets/comment/emotions/zaijian.gif "[zaijian]")
![[kafei]](/static/assets/comment/emotions/kafei.gif "[kafei]")
![[love]](/static/assets/comment/emotions/love.gif "[love]")
![[pizui]](/static/assets/comment/emotions/pizui.gif "[pizui]")
![[huitou]](/static/assets/comment/emotions/huitou.gif "[huitou]")
![[tiao]](/static/assets/comment/emotions/tiao.gif "[tiao]")
![[liwu]](/static/assets/comment/emotions/liwu.gif "[liwu]")
![[zhutou]](/static/assets/comment/emotions/zhutou.gif "[zhutou]")
![[e]](/static/assets/comment/emotions/e.gif "[e]")
![[qiang]](/static/assets/comment/emotions/qiang.gif "[qiang]")
![[youtaiji]](/static/assets/comment/emotions/youtaiji.gif "[youtaiji]")
![[zuohengheng]](/static/assets/comment/emotions/zuohengheng.gif "[zuohengheng]")
![[huaixiao]](/static/assets/comment/emotions/huaixiao.gif "[huaixiao]")
![[gouyin]](/static/assets/comment/emotions/gouyin.gif "[gouyin]")
![[keai]](/static/assets/comment/emotions/keai.gif "[keai]")
![[tiaosheng]](/static/assets/comment/emotions/tiaosheng.gif "[tiaosheng]")
![[daku]](/static/assets/comment/emotions/daku.gif "[daku]")
![[weiqu]](/static/assets/comment/emotions/weiqu.gif "[weiqu]")
![[lanqiu]](/static/assets/comment/emotions/lanqiu.gif "[lanqiu]")
![[zhemo]](/static/assets/comment/emotions/zhemo.gif "[zhemo]")
![[xia]](/static/assets/comment/emotions/xia.gif "[xia]")
![[fan]](/static/assets/comment/emotions/fan.gif "[fan]")
![[yun]](/static/assets/comment/emotions/yun.gif "[yun]")
![[youhengheng]](/static/assets/comment/emotions/youhengheng.gif "[youhengheng]")
![[chong]](/static/assets/comment/emotions/chong.gif "[chong]")
![[pijiu]](/static/assets/comment/emotions/pijiu.gif "[pijiu]")
![[dajiao]](/static/assets/comment/emotions/dajiao.gif "[dajiao]")
![[dao]](/static/assets/comment/emotions/dao.gif "[dao]")
![[diaoxie]](/static/assets/comment/emotions/diaoxie.gif "[diaoxie]")
![[liuhan]](/static/assets/comment/emotions/liuhan.gif "[liuhan]")
![[haha]](/static/assets/comment/emotions/haha.gif "[haha]")
![[xu]](/static/assets/comment/emotions/xu.gif "[xu]")
![[zhuakuang]](/static/assets/comment/emotions/zhuakuang.gif "[zhuakuang]")
![[zhuanquan]](/static/assets/comment/emotions/zhuanquan.gif "[zhuanquan]")
![[no]](/static/assets/comment/emotions/no.gif "[no]")
![[ok]](/static/assets/comment/emotions/ok.gif "[ok]")
![[feiwen]](/static/assets/comment/emotions/feiwen.gif "[feiwen]")
![[taiyang]](/static/assets/comment/emotions/taiyang.gif "[taiyang]")
![[woshou]](/static/assets/comment/emotions/woshou.gif "[woshou]")
![[zuqiu]](/static/assets/comment/emotions/zuqiu.gif "[zuqiu]")
![[xigua]](/static/assets/comment/emotions/xigua.gif "[xigua]")
![[hua]](/static/assets/comment/emotions/hua.gif "[hua]")
![[tu]](/static/assets/comment/emotions/tu.gif "[tu]")
![[tiaowu]](/static/assets/comment/emotions/tiaowu.gif "[tiaowu]")
![[ma]](/static/assets/comment/emotions/ma.gif "[ma]")
![[baiyan]](/static/assets/comment/emotions/baiyan.gif "[baiyan]")
![[zhadan]](/static/assets/comment/emotions/zhadan.gif "[zhadan]")
![[weixiao]](/static/assets/comment/emotions/weixiao.gif "[weixiao]")
![[wen]](/static/assets/comment/emotions/wen.gif "[wen]")
![[dabing]](/static/assets/comment/emotions/dabing.gif "[dabing]")
![[xianwen]](/static/assets/comment/emotions/xianwen.gif "[xianwen]")
![[shuijiao]](/static/assets/comment/emotions/shuijiao.gif "[shuijiao]")
![[yongbao]](/static/assets/comment/emotions/yongbao.gif "[yongbao]")
![[kelian]](/static/assets/comment/emotions/kelian.gif "[kelian]")
![[pingpang]](/static/assets/comment/emotions/pingpang.gif "[pingpang]")
![[danu]](/static/assets/comment/emotions/danu.gif "[danu]")
![[geili]](/static/assets/comment/emotions/geili.gif "[geili]")
![[wabi]](/static/assets/comment/emotions/wabi.gif "[wabi]")
![[kuaikule]](/static/assets/comment/emotions/kuaikule.gif "[kuaikule]")
![[zuotaiji]](/static/assets/comment/emotions/zuotaiji.gif "[zuotaiji]")
![[tuzi]](/static/assets/comment/emotions/tuzi.gif "[tuzi]")
![[bishi]](/static/assets/comment/emotions/bishi.gif "[bishi]")
![[caidao]](/static/assets/comment/emotions/caidao.gif "[caidao]")
![[dabian]](/static/assets/comment/emotions/dabian.gif "[dabian]")
![[fanu]](/static/assets/comment/emotions/fanu.gif "[fanu]")
![[guzhang]](/static/assets/comment/emotions/guzhang.gif "[guzhang]")
![[se]](/static/assets/comment/emotions/se.gif "[se]")
![[chajin]](/static/assets/comment/emotions/chajin.gif "[chajin]")
![[bizui]](/static/assets/comment/emotions/bizui.gif "[bizui]")
![[deyi]](/static/assets/comment/emotions/deyi.gif "[deyi]")
![[ku]](/static/assets/comment/emotions/ku.gif "[ku]")
![[huishou]](/static/assets/comment/emotions/huishou.gif "[huishou]")
![[yinxian]](/static/assets/comment/emotions/yinxian.gif "[yinxian]")
![[haixiu]](/static/assets/comment/emotions/haixiu.gif "[haixiu]")
CogVLM & CogAgent Альтернативи
Больше Альтернативи-

GLM-4-9B - это версия с открытым исходным кодом последнего поколения предварительно обученных моделей в серии GLM-4, выпущенных компанией Zhipu AI.
-

Mini-Gemini поддерживает ряд плотных языковых моделей MoE (LLM) от 2B до 34B с одновременным пониманием, рассуждением и генерацией изображений. Мы создаем этот репозиторий на основе LLaVA.
-

С 8 миллиардами параметров модель превосходит по общему качеству работы проприетарные модели, такие как GPT-4V-1106, Gemini Pro, Qwen-VL-Max и Claude 3.
-

Усовершенствуйте языковые модели, улучшите производительность и получите точные результаты. WizardLM — это универсальный инструмент для задач кодирования, математики и обработки естественного языка.
-

Высокопроизводительный и экономичный по памяти механизм вывода и обслуживания для LLMs