 Berkeley Function-Calling Leaderboard
Berkeley Function-Calling Leaderboard
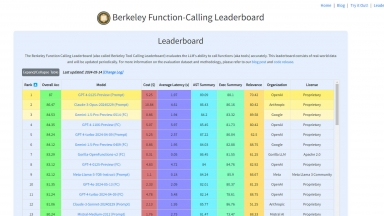
探索柏克萊函數呼叫排行榜(也稱為柏克萊工具呼叫排行榜),了解大型語言模型 (LLM) 準確呼叫函數(又稱工具)的能力。
 Huggingface's Open LLM Leaderboard
Huggingface's Open LLM Leaderboard
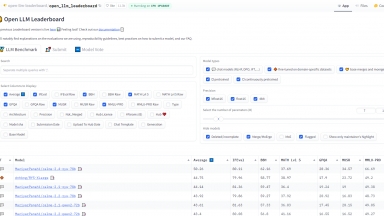
Huggingface 的 Open LLM Leaderboard 目標是促進語言模型評估的開放合作與透明度。
Berkeley Function-Calling Leaderboard
| Launched | |
| Pricing Model | Free |
| Starting Price | |
| Tech used | Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube |
| Tag | Data Analysis,Data visualization,Test Automation,A/B Testing,LLMs,LLM benchmark leaderboard |
Huggingface's Open LLM Leaderboard
| Launched | |
| Pricing Model | Free |
| Starting Price | |
| Tech used | |
| Tag | LLM benchmark leaderboard,Natural Language Processing,Data Analysis,LLMs |
Berkeley Function-Calling Leaderboard Rank/Visit
| Global Rank | |
| Country | |
| Month Visit |
Top 5 Countries
Traffic Sources
Huggingface's Open LLM Leaderboard Rank/Visit
| Global Rank | |
| Country | |
| Month Visit |
Top 5 Countries
Traffic Sources
What are some alternatives?
When comparing Berkeley Function-Calling Leaderboard and Huggingface's Open LLM Leaderboard, you can also consider the following products
Klu LLM Benchmarks - 即時的 Klu.ai 資料為此排行榜提供動力,用於評估 LLM 供應商,讓您能夠根據自身需求選擇最佳的 API 和模型。
Hugging Face Agent Leaderboard - 透過 Agent Leaderboard 選擇最符合您需求的 AI 代理程式——此排行榜提供橫跨 14 項基準的公正、真實效能見解。
LiveBench - LiveBench 是一個大型語言模型基準測試,每月從不同來源獲得新問題和客觀答案,以進行準確評分。目前包含 6 個類別的 18 個任務,並將陸續增加更多任務。
Scale Leaderboard - SEAL 排行榜顯示,OpenAI 的 GPT 系列大型語言模型 (LLM) 在用於評估 AI 模型的四個初始領域中的三個領域中排名第一,Anthropic PBC 的熱門 Claude 3 Opus 在第四個類別中奪得第一。Google LLC 的 Gemini 模型也表現出色,在幾個領域中與 GPT 模型並列第一。