
What is Huggingface's Open LLM Leaderboard?
Huggingface 的 Open LLM 排行榜在其前身的基础上进行了全面改进,前身已经成为超过 200 万访问者的重要枢纽。现在,排行榜提供更具挑战性的基准测试、改进的评估流程以及更佳的用户体验。排行榜的主要目标是通过克服现有基准测试的局限性(例如易用性和数据污染),来提炼出 LLM 的真正潜力,确保模型性能反映真正的进步,而不是优化的指标。
主要功能
新基准测试:引入了六个严格的基准测试,以测试从知识和推理到复杂数学和指令遵循的各种技能。
标准化评分:新的评分系统,对结果进行标准化,以考虑不同基准测试之间的难度差异。
更新的评估工具:与 EleutherAI 合作,更新了评估工具,以确保评估保持一致性和可重复性。
维护者推荐:来自各种来源的顶级模型的精选列表,为用户提供可靠的起点。
社区投票:投票系统允许社区优先考虑要评估的模型,确保最受期待的模型能够及时得到评估。
用例
研究与开发:研究人员可以根据详细的性能指标识别最有希望的模型,以便进一步开发或定制。
商业实施:寻求将 LLM 集成到其产品的公司可以选择在相关任务和领域表现出色的模型。
教育目的:教育工作者和学生可以使用排行榜来了解 LLM 能力的现状以及该领域的进展。
结论
Huggingface 的 Open LLM 排行榜不仅仅是更新,它是在 LLM 评估方面的一次重大进步。通过提供更准确、更具挑战性和社区驱动的评估,它为下一代语言模型铺平了道路。探索排行榜,贡献您的模型,并成为塑造 AI 未来的一部分。
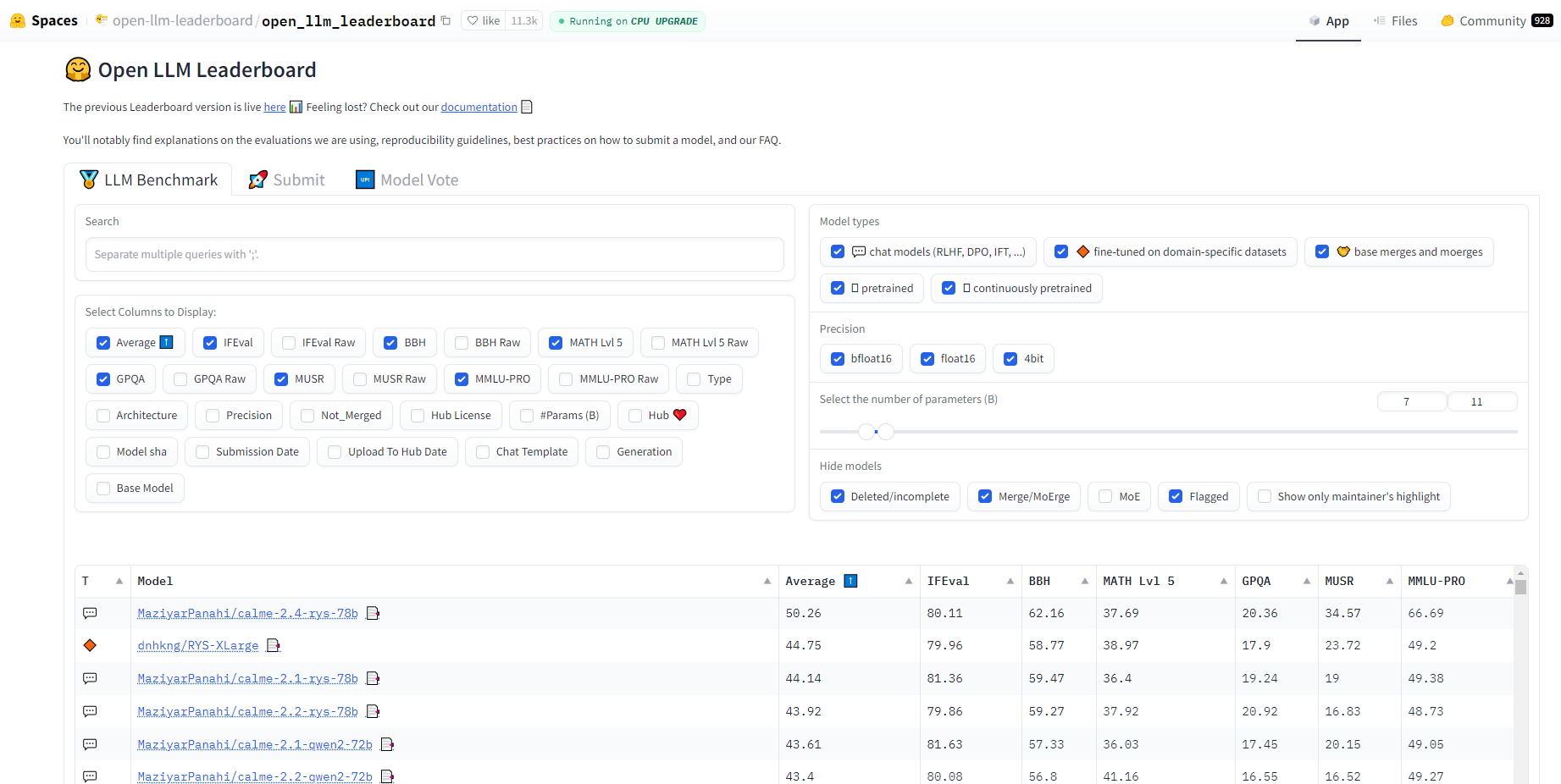
More information on Huggingface's Open LLM Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Huggingface's Open LLM Leaderboard was manually vetted by our editorial team and was first featured on 2024-09-14.
Related Searches
Huggingface's Open LLM Leaderboard 替代方案
更多 替代方案-

-

探索伯克利函数调用排行榜(也称为伯克利工具调用排行榜),了解大型语言模型 (LLM) 准确调用函数(又称工具)的能力。
-

-

-
