
What is LlamaEdge?
想象一下,你能够直接在设备上运行和微调大型语言模型(LLM),无需依赖云端,无需复杂的设置,也无需牺牲性能——这正是 LlamaEdge 所提供的强大功能。无论你是构建 AI 驱动应用的开发者,还是寻求部署私有化、定制化 LLM 的企业,LlamaEdge 都是你翘首以盼的轻量级、快速且便携的解决方案。
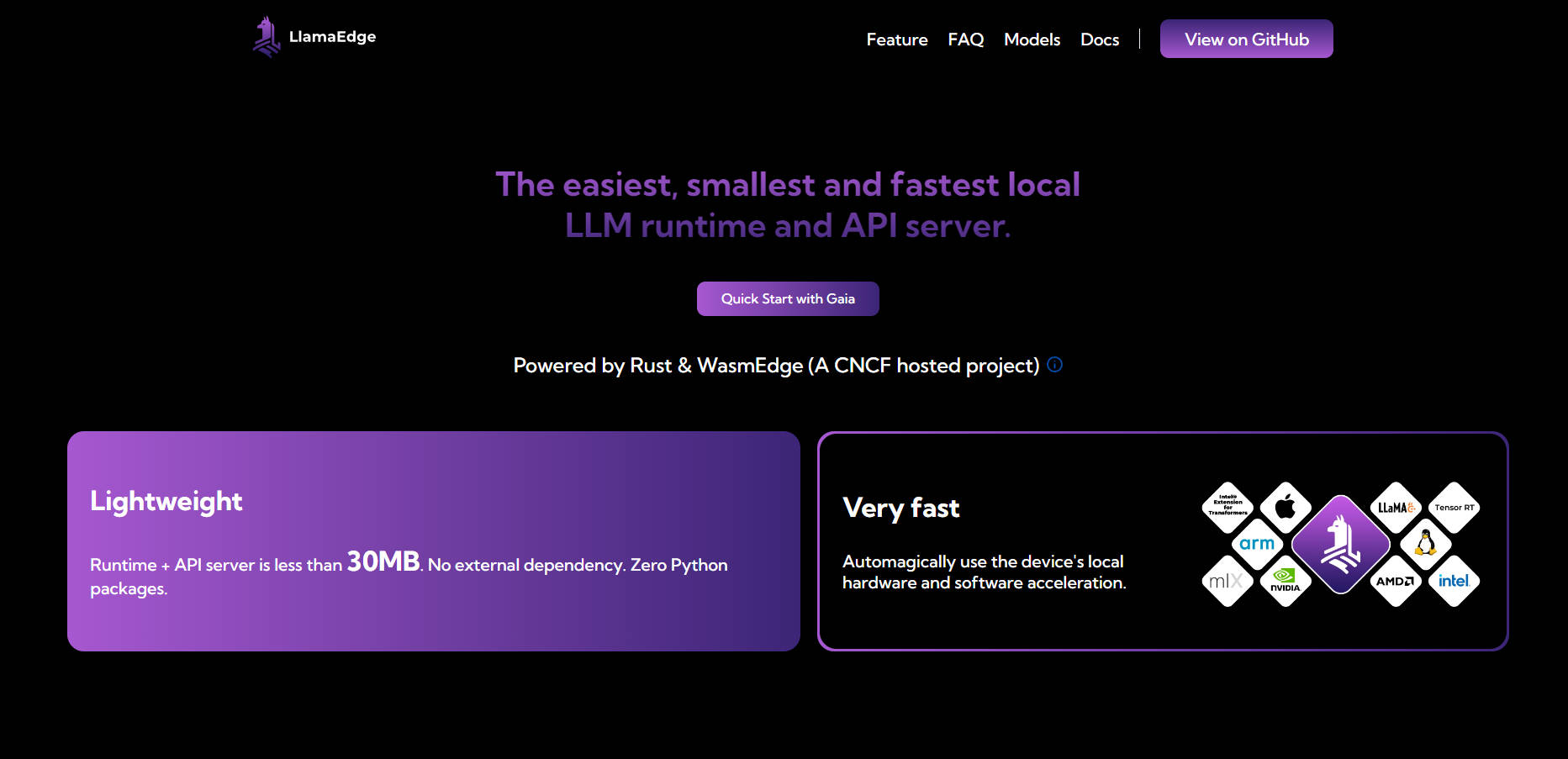
LlamaEdge 运行时小于 30MB,且零依赖,旨在简化在本地或边缘运行 LLM 的流程。它充分利用设备的硬件资源,确保原生速度和无缝的跨平台部署。
主要特性
💡 在本地或边缘运行 LLM
直接在你的设备上部署和微调 LLM,确保数据隐私,并摆脱对昂贵云服务的依赖。
🌐 跨平台兼容性
一次编写代码,即可在任何地方部署——无论是 MacBook、NVIDIA GPU 还是边缘设备。无需为不同的平台重建或重新测试。
⚡ 轻量且快速
LlamaEdge 运行时小于 30MB,且没有外部依赖,非常轻巧。它能够自动利用设备的硬件加速功能,以获得最佳性能。
🛠️ 模块化设计,便于定制
像乐高积木一样,使用 Rust 或 JavaScript 组装你的 LLM 代理和应用程序。创建紧凑、自包含的二进制文件,可以在各种设备上无缝运行。
🔒 增强的隐私和安全性
将你的数据保存在本地,确保安全。LlamaEdge 在沙盒环境中运行,无需 root 权限,并确保你的交互保持私密性。
应用场景
构建私有 AI 助手
创建完全在你的设备上运行的 AI 驱动的聊天机器人或虚拟助手,在保护敏感数据的同时,提供快速、响应式的交互。开发定制化的 LLM 应用
针对特定行业或用例微调 LLM——无论是法律文档分析、客户支持还是医疗诊断——而无需基于云的解决方案。在边缘设备上部署 AI
将 AI 功能带到 IoT 传感器或移动应用等边缘设备,实现实时的决策,而无需担心延迟或连接问题。
为什么选择 LlamaEdge?
经济高效: 避免托管 LLM API 的高昂成本以及管理云基础设施的复杂性。
可定制: 根据你的特定需求定制 LLM,而无需受通用模型的限制。
便携: 使用单个二进制文件,在不同的平台和设备上部署你的应用程序。
面向未来: 保持领先,支持多模态模型、替代运行时和新兴 AI 技术。
常见问题解答
问:LlamaEdge 与基于 Python 的解决方案相比如何?
答:像 PyTorch 这样基于 Python 的解决方案带有庞大的依赖项,并且在生产级别的推理中速度较慢。另一方面,LlamaEdge 轻量级(小于 30MB)、速度更快,并且没有依赖冲突。
问:LlamaEdge 与 GPU 和硬件加速器兼容吗?
答:当然。LlamaEdge 能够自动利用设备的硬件加速功能,确保在 CPU、GPU 和 NPU 上实现原生速度。
问:我可以将 LlamaEdge 与现有的开源模型一起使用吗?
答:可以。LlamaEdge 支持各种 AI/LLM 模型,包括整个 Llama2 系列,并允许你针对特定需求进行微调。
问:是什么让 LlamaEdge 比其他解决方案更安全?
答:LlamaEdge 在沙盒环境中运行,无需 root 权限,并确保你的数据永远不会离开你的设备,这使其成为敏感应用更安全的选择。
准备好开始了吗?
有了 LlamaEdge,在本地运行和微调 LLM 从未如此简单。无论你是构建 AI 驱动的应用程序,还是在边缘设备上部署模型,LlamaEdge 都能让你事半功倍。立即安装,体验本地 LLM 部署的未来。
More information on LlamaEdge
Launched
2024-01
Pricing Model
Free
Starting Price
Global Rank
9690627
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Fastly,Google Fonts,GitHub Pages,Gzip,Varnish
Top 5 Countries
100%
United States
Traffic Sources
66.33%
20.59%
6.99%
5.01%
0.48%
0.11%
Direct
Search
Referrals
Social
Paid Referrals
Mail
LlamaEdge was manually vetted by our editorial team and was first featured on 2025-02-11.
![[dangao]](/static/assets/comment/emotions/dangao.gif "[dangao]")
![[qiu]](/static/assets/comment/emotions/qiu.gif "[qiu]")
![[fadou]](/static/assets/comment/emotions/fadou.gif "[fadou]")
![[tiaopi]](/static/assets/comment/emotions/tiaopi.gif "[tiaopi]")
![[fadai]](/static/assets/comment/emotions/fadai.gif "[fadai]")
![[xinsui]](/static/assets/comment/emotions/xinsui.gif "[xinsui]")
![[ruo]](/static/assets/comment/emotions/ruo.gif "[ruo]")
![[jingkong]](/static/assets/comment/emotions/jingkong.gif "[jingkong]")
![[quantou]](/static/assets/comment/emotions/quantou.gif "[quantou]")
![[gangga]](/static/assets/comment/emotions/gangga.gif "[gangga]")
![[da]](/static/assets/comment/emotions/da.gif "[da]")
![[touxiao]](/static/assets/comment/emotions/touxiao.gif "[touxiao]")
![[ciya]](/static/assets/comment/emotions/ciya.gif "[ciya]")
![[liulei]](/static/assets/comment/emotions/liulei.gif "[liulei]")
![[fendou]](/static/assets/comment/emotions/fendou.gif "[fendou]")
![[kiss]](/static/assets/comment/emotions/kiss.gif "[kiss]")
![[aoman]](/static/assets/comment/emotions/aoman.gif "[aoman]")
![[kulou]](/static/assets/comment/emotions/kulou.gif "[kulou]")
![[yueliang]](/static/assets/comment/emotions/yueliang.gif "[yueliang]")
![[lenghan]](/static/assets/comment/emotions/lenghan.gif "[lenghan]")
![[kun]](/static/assets/comment/emotions/kun.gif "[kun]")
![[meng]](/static/assets/comment/emotions/meng.gif "[meng]")
![[shenma]](/static/assets/comment/emotions/shenma.gif "[shenma]")
![[peifu]](/static/assets/comment/emotions/peifu.gif "[peifu]")
![[qinqin]](/static/assets/comment/emotions/qinqin.gif "[qinqin]")
![[nanguo]](/static/assets/comment/emotions/nanguo.gif "[nanguo]")
![[hufen]](/static/assets/comment/emotions/hufen.gif "[hufen]")
![[shuai]](/static/assets/comment/emotions/shuai.gif "[shuai]")
![[jingya]](/static/assets/comment/emotions/jingya.gif "[jingya]")
![[cahan]](/static/assets/comment/emotions/cahan.gif "[cahan]")
![[shengli]](/static/assets/comment/emotions/shengli.gif "[shengli]")
![[qioudale]](/static/assets/comment/emotions/qioudale.gif "[qioudale]")
![[cheer]](/static/assets/comment/emotions/cheer.gif "[cheer]")
![[ketou]](/static/assets/comment/emotions/ketou.gif "[ketou]")
![[shandian]](/static/assets/comment/emotions/shandian.gif "[shandian]")
![[haqian]](/static/assets/comment/emotions/haqian.gif "[haqian]")
![[jidong]](/static/assets/comment/emotions/jidong.gif "[jidong]")
![[zaijian]](/static/assets/comment/emotions/zaijian.gif "[zaijian]")
![[kafei]](/static/assets/comment/emotions/kafei.gif "[kafei]")
![[love]](/static/assets/comment/emotions/love.gif "[love]")
![[pizui]](/static/assets/comment/emotions/pizui.gif "[pizui]")
![[huitou]](/static/assets/comment/emotions/huitou.gif "[huitou]")
![[tiao]](/static/assets/comment/emotions/tiao.gif "[tiao]")
![[liwu]](/static/assets/comment/emotions/liwu.gif "[liwu]")
![[zhutou]](/static/assets/comment/emotions/zhutou.gif "[zhutou]")
![[e]](/static/assets/comment/emotions/e.gif "[e]")
![[qiang]](/static/assets/comment/emotions/qiang.gif "[qiang]")
![[youtaiji]](/static/assets/comment/emotions/youtaiji.gif "[youtaiji]")
![[zuohengheng]](/static/assets/comment/emotions/zuohengheng.gif "[zuohengheng]")
![[huaixiao]](/static/assets/comment/emotions/huaixiao.gif "[huaixiao]")
![[gouyin]](/static/assets/comment/emotions/gouyin.gif "[gouyin]")
![[keai]](/static/assets/comment/emotions/keai.gif "[keai]")
![[tiaosheng]](/static/assets/comment/emotions/tiaosheng.gif "[tiaosheng]")
![[daku]](/static/assets/comment/emotions/daku.gif "[daku]")
![[weiqu]](/static/assets/comment/emotions/weiqu.gif "[weiqu]")
![[lanqiu]](/static/assets/comment/emotions/lanqiu.gif "[lanqiu]")
![[zhemo]](/static/assets/comment/emotions/zhemo.gif "[zhemo]")
![[xia]](/static/assets/comment/emotions/xia.gif "[xia]")
![[fan]](/static/assets/comment/emotions/fan.gif "[fan]")
![[yun]](/static/assets/comment/emotions/yun.gif "[yun]")
![[youhengheng]](/static/assets/comment/emotions/youhengheng.gif "[youhengheng]")
![[chong]](/static/assets/comment/emotions/chong.gif "[chong]")
![[pijiu]](/static/assets/comment/emotions/pijiu.gif "[pijiu]")
![[dajiao]](/static/assets/comment/emotions/dajiao.gif "[dajiao]")
![[dao]](/static/assets/comment/emotions/dao.gif "[dao]")
![[diaoxie]](/static/assets/comment/emotions/diaoxie.gif "[diaoxie]")
![[liuhan]](/static/assets/comment/emotions/liuhan.gif "[liuhan]")
![[haha]](/static/assets/comment/emotions/haha.gif "[haha]")
![[xu]](/static/assets/comment/emotions/xu.gif "[xu]")
![[zhuakuang]](/static/assets/comment/emotions/zhuakuang.gif "[zhuakuang]")
![[zhuanquan]](/static/assets/comment/emotions/zhuanquan.gif "[zhuanquan]")
![[no]](/static/assets/comment/emotions/no.gif "[no]")
![[ok]](/static/assets/comment/emotions/ok.gif "[ok]")
![[feiwen]](/static/assets/comment/emotions/feiwen.gif "[feiwen]")
![[taiyang]](/static/assets/comment/emotions/taiyang.gif "[taiyang]")
![[woshou]](/static/assets/comment/emotions/woshou.gif "[woshou]")
![[zuqiu]](/static/assets/comment/emotions/zuqiu.gif "[zuqiu]")
![[xigua]](/static/assets/comment/emotions/xigua.gif "[xigua]")
![[hua]](/static/assets/comment/emotions/hua.gif "[hua]")
![[tu]](/static/assets/comment/emotions/tu.gif "[tu]")
![[tiaowu]](/static/assets/comment/emotions/tiaowu.gif "[tiaowu]")
![[ma]](/static/assets/comment/emotions/ma.gif "[ma]")
![[baiyan]](/static/assets/comment/emotions/baiyan.gif "[baiyan]")
![[zhadan]](/static/assets/comment/emotions/zhadan.gif "[zhadan]")
![[weixiao]](/static/assets/comment/emotions/weixiao.gif "[weixiao]")
![[wen]](/static/assets/comment/emotions/wen.gif "[wen]")
![[dabing]](/static/assets/comment/emotions/dabing.gif "[dabing]")
![[xianwen]](/static/assets/comment/emotions/xianwen.gif "[xianwen]")
![[shuijiao]](/static/assets/comment/emotions/shuijiao.gif "[shuijiao]")
![[yongbao]](/static/assets/comment/emotions/yongbao.gif "[yongbao]")
![[kelian]](/static/assets/comment/emotions/kelian.gif "[kelian]")
![[pingpang]](/static/assets/comment/emotions/pingpang.gif "[pingpang]")
![[danu]](/static/assets/comment/emotions/danu.gif "[danu]")
![[geili]](/static/assets/comment/emotions/geili.gif "[geili]")
![[wabi]](/static/assets/comment/emotions/wabi.gif "[wabi]")
![[kuaikule]](/static/assets/comment/emotions/kuaikule.gif "[kuaikule]")
![[zuotaiji]](/static/assets/comment/emotions/zuotaiji.gif "[zuotaiji]")
![[tuzi]](/static/assets/comment/emotions/tuzi.gif "[tuzi]")
![[bishi]](/static/assets/comment/emotions/bishi.gif "[bishi]")
![[caidao]](/static/assets/comment/emotions/caidao.gif "[caidao]")
![[dabian]](/static/assets/comment/emotions/dabian.gif "[dabian]")
![[fanu]](/static/assets/comment/emotions/fanu.gif "[fanu]")
![[guzhang]](/static/assets/comment/emotions/guzhang.gif "[guzhang]")
![[se]](/static/assets/comment/emotions/se.gif "[se]")
![[chajin]](/static/assets/comment/emotions/chajin.gif "[chajin]")
![[bizui]](/static/assets/comment/emotions/bizui.gif "[bizui]")
![[deyi]](/static/assets/comment/emotions/deyi.gif "[deyi]")
![[ku]](/static/assets/comment/emotions/ku.gif "[ku]")
![[huishou]](/static/assets/comment/emotions/huishou.gif "[huishou]")
![[yinxian]](/static/assets/comment/emotions/yinxian.gif "[yinxian]")
![[haixiu]](/static/assets/comment/emotions/haixiu.gif "[haixiu]")
LlamaEdge 替代方案
更多 替代方案-

-

-

-

WordLlama 是一款用于自然语言处理 (NLP) 的工具,它从大型语言模型 (LLM) 中循环利用组件,以创建类似于 GloVe、Word2Vec 或 FastText 的高效紧凑的词表示。
-
