
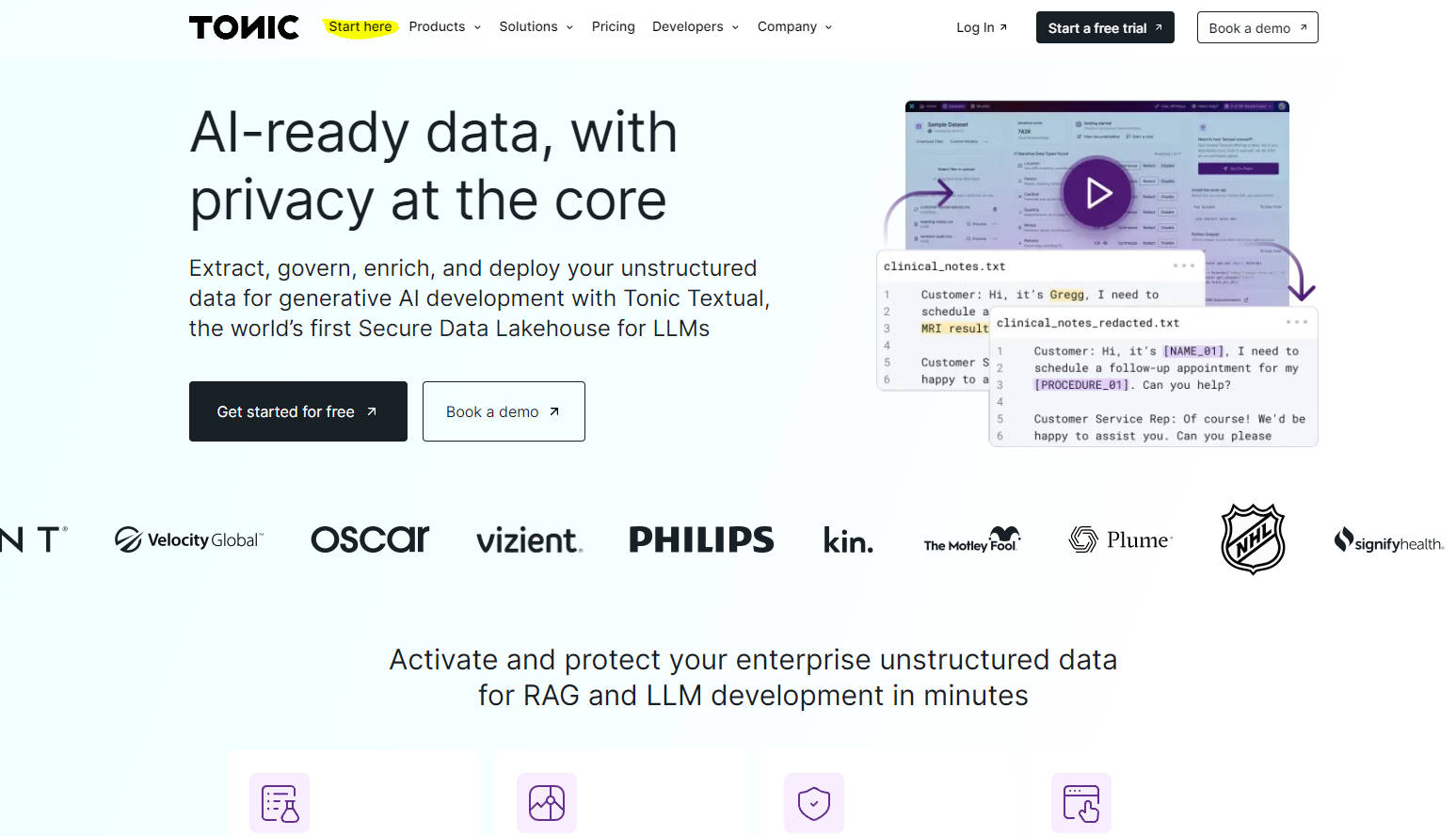
What is Tonic Textual?
Tonic Textual 作为全球首个专为大型语言模型 (LLM) 设计的安全数据湖,站在人工智能创新的前沿。这个开创性的平台无缝地统一、保护和准备非结构化数据,使企业能够充分利用生成式人工智能的潜力。Tonic Textual 以隐私和效率为核心,使用户能够在几分钟内提取、治理、丰富和部署非结构化数据,用于人工智能应用。
主要功能
自动化数据提取 ?:构建高效的管道,直接从云数据存储中自动提取、结构化和标准化非结构化数据,使其成为人工智能就绪格式。
高级数据丰富 ?:利用 Textual 的命名实体识别 (NER) 模型,通过添加高质量元数据和自定义实体标签,来提升递归自动编码器 (RAG) 的性能和准确性。
强大的数据治理 ?:通过发现、标记和删除敏感实体,保护敏感和专有数据,防止模型记忆和数据泄露。使用合成数据重新填充删除内容,以保持语义真实性。
无缝集成和部署 ?:与领先的嵌入模型、向量数据库和人工智能开发平台集成,用于 RAG 和微调,方便在后续人工智能流程中使用数据。
用例
金融机构:Tonic Textual 通过自动识别和删除文本数据中的敏感信息,帮助金融机构遵守 GDPR 和其他数据隐私法规。
医疗保健提供者:在医疗保健领域,该平台通过检测和保护非结构化医疗记录中的个人健康信息,确保患者的机密性。
律师事务所:法律专业人士使用 Tonic Textual 来管理和删除法律文件中的敏感信息,在利用人工智能进行法律研究和分析的同时,维护客户隐私。
结论
Tonic Textual 不仅仅是一个数据管理工具,它是一场关于企业如何与非结构化数据交互的革命。通过优先考虑隐私和效率,Tonic Textual 释放了生成式人工智能的潜力,同时确保敏感信息得到保护。拥抱 Tonic Textual,开启人工智能的未来,在那里,数据科学得到最大化,数据准备得到最小化。
More information on Tonic Textual
Launched
2017-12
Pricing Model
Free Trial
Starting Price
Global Rank
466366
Follow
Month Visit
78.1K
Tech used
Google Tag Manager,HubSpot Analytics,Microsoft Clarity,Webflow,Amazon AWS CloudFront,JSDelivr,Google Fonts,JavaScript Cookie,jQuery,Gzip,OpenGraph
Top 5 Countries
54.93%
3.01%
2.83%
2.43%
2.21%
United States
India
Vietnam
France
Nigeria
Traffic Sources
3.07%
1.24%
0.1%
9.41%
43.2%
42.96%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Tonic Textual was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Tonic Textual 替代方案
更多 替代方案-

-

-

Tensorlake Cloud 是一个文档导入和数据编排的平台。它具备类人般的版面理解能力,可以解析现实世界中的各种文档,并支持构建可大规模扩展、随时可投入生产的基于 Python 的工作流。
-

-
