
What is Tonic Textual?
Tonic Textual 站在 AI 創新的最前沿,是全球首個專為大型語言模型 (LLM) 設計的安全數據湖。這個開創性的平台無縫地整合、保護和準備非結構化數據,賦能企業充分發揮生成式 AI 的潛力。Tonic Textual 關注隱私和效率,使用戶能夠在幾分鐘內提取、管理、豐富和部署其非結構化數據,以用於 AI 應用。
主要功能
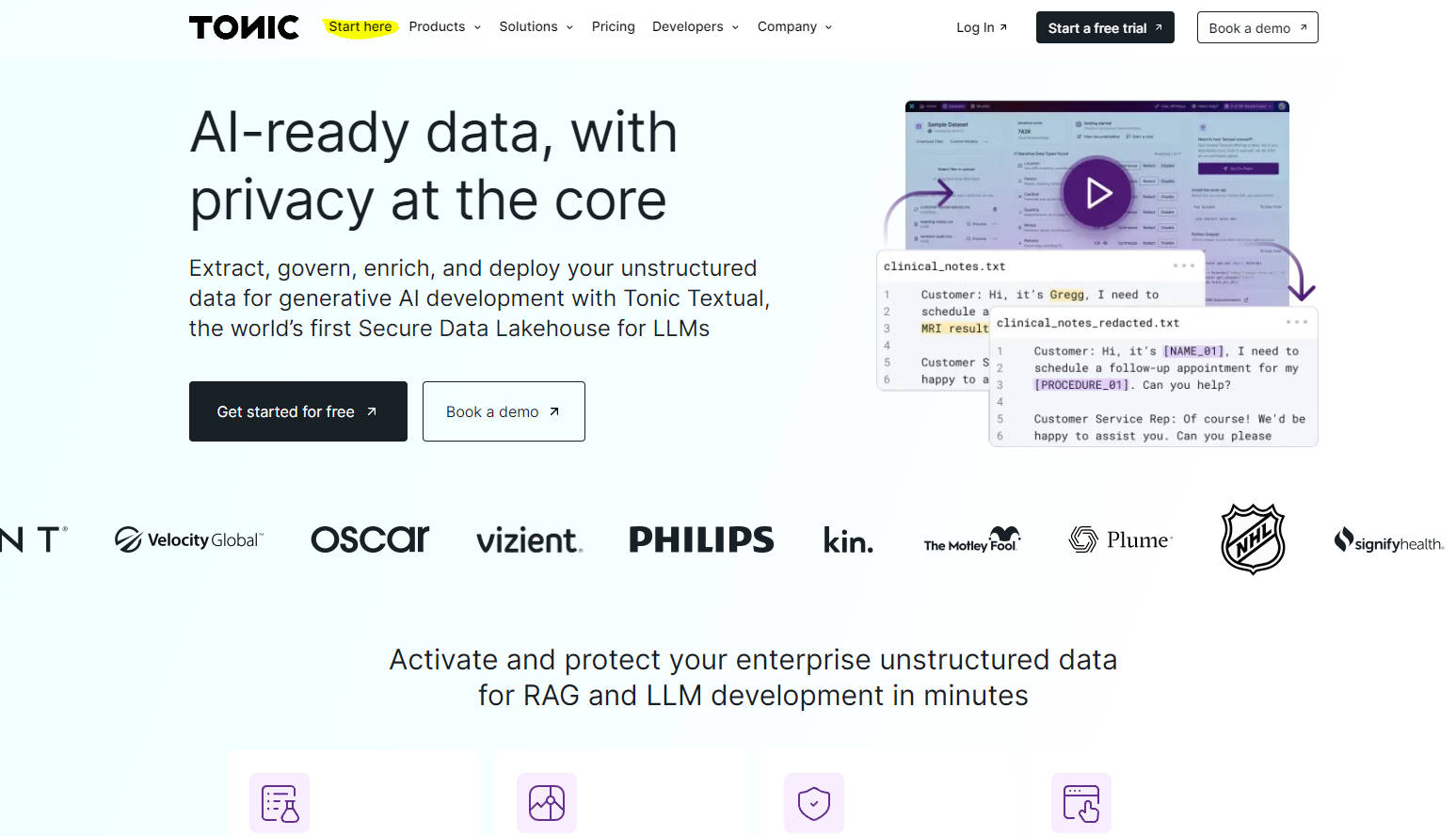
自動數據提取 ?:建立高效的管道,直接從雲數據存儲中自動提取、結構化和標準化非結構化數據,轉換為 AI 可用的格式。
高級數據豐富 ?:利用 Textual 的命名實體識別 (NER) 模型,通過為數據添加高質量的元數據和自定義實體標籤,提升遞迴自動編碼器 (RAG) 的性能和準確性。
強大的數據治理 ?:通過發現、標記和隱藏敏感實體來保護敏感和專有數據,防止模型記憶和數據洩漏。使用合成數據重新播種隱藏數據,以保持語義真實性。
無縫集成和部署 ?:與領先的嵌入模型、向量數據庫和 AI 開發平台集成,用於 RAG 和微調,促進數據在後續 AI 流程中的使用。
用例
金融機構:Tonic Textual 協助金融機構通過自動識別和隱藏文本數據中的敏感信息,以符合 GDPR 和其他數據隱私法規。
醫療保健提供者:在醫療保健領域,該平台通過檢測和保護非結構化醫療記錄中的個人健康信息,來確保患者的保密性。
律師事務所:法律專業人士使用 Tonic Textual 管理和隱藏法律文檔中的敏感信息,在利用 AI 進行法律研究和分析的同時,維護客戶隱私。
結論
Tonic Textual 不僅僅是一個數據管理工具,它是一種企業與非結構化數據交互方式的革命。通過優先考慮隱私和效率,Tonic Textual 解鎖了生成式 AI 的潛力,同時確保敏感信息得到保護。擁抱 Tonic Textual 的 AI 未來,數據科學最大化,數據準備最小化。
More information on Tonic Textual
Launched
Pricing Model
Free Trial
Starting Price
Global Rank
768357
Follow
Month Visit
46.6K
Tech used
Google Tag Manager,HubSpot Analytics,Microsoft Clarity,Webflow,Amazon AWS CloudFront,JSDelivr,Google Fonts,JavaScript Cookie,jQuery,Gzip,OpenGraph
Top 5 Countries
25.51%
9.76%
5.75%
5.49%
4.54%
United States
United Kingdom
India
Canada
Spain
Traffic Sources
49.22%
38.14%
9.44%
2.28%
0.81%
0.11%
Search
Direct
Referrals
Social
Paid Referrals
Mail
Tonic Textual was manually vetted by our editorial team and was first featured on September 4th 2025.
Related Searches
![[dangao]](/static/assets/comment/emotions/dangao.gif "[dangao]")
![[qiu]](/static/assets/comment/emotions/qiu.gif "[qiu]")
![[fadou]](/static/assets/comment/emotions/fadou.gif "[fadou]")
![[tiaopi]](/static/assets/comment/emotions/tiaopi.gif "[tiaopi]")
![[fadai]](/static/assets/comment/emotions/fadai.gif "[fadai]")
![[xinsui]](/static/assets/comment/emotions/xinsui.gif "[xinsui]")
![[ruo]](/static/assets/comment/emotions/ruo.gif "[ruo]")
![[jingkong]](/static/assets/comment/emotions/jingkong.gif "[jingkong]")
![[quantou]](/static/assets/comment/emotions/quantou.gif "[quantou]")
![[gangga]](/static/assets/comment/emotions/gangga.gif "[gangga]")
![[da]](/static/assets/comment/emotions/da.gif "[da]")
![[touxiao]](/static/assets/comment/emotions/touxiao.gif "[touxiao]")
![[ciya]](/static/assets/comment/emotions/ciya.gif "[ciya]")
![[liulei]](/static/assets/comment/emotions/liulei.gif "[liulei]")
![[fendou]](/static/assets/comment/emotions/fendou.gif "[fendou]")
![[kiss]](/static/assets/comment/emotions/kiss.gif "[kiss]")
![[aoman]](/static/assets/comment/emotions/aoman.gif "[aoman]")
![[kulou]](/static/assets/comment/emotions/kulou.gif "[kulou]")
![[yueliang]](/static/assets/comment/emotions/yueliang.gif "[yueliang]")
![[lenghan]](/static/assets/comment/emotions/lenghan.gif "[lenghan]")
![[kun]](/static/assets/comment/emotions/kun.gif "[kun]")
![[meng]](/static/assets/comment/emotions/meng.gif "[meng]")
![[shenma]](/static/assets/comment/emotions/shenma.gif "[shenma]")
![[peifu]](/static/assets/comment/emotions/peifu.gif "[peifu]")
![[qinqin]](/static/assets/comment/emotions/qinqin.gif "[qinqin]")
![[nanguo]](/static/assets/comment/emotions/nanguo.gif "[nanguo]")
![[hufen]](/static/assets/comment/emotions/hufen.gif "[hufen]")
![[shuai]](/static/assets/comment/emotions/shuai.gif "[shuai]")
![[jingya]](/static/assets/comment/emotions/jingya.gif "[jingya]")
![[cahan]](/static/assets/comment/emotions/cahan.gif "[cahan]")
![[shengli]](/static/assets/comment/emotions/shengli.gif "[shengli]")
![[qioudale]](/static/assets/comment/emotions/qioudale.gif "[qioudale]")
![[cheer]](/static/assets/comment/emotions/cheer.gif "[cheer]")
![[ketou]](/static/assets/comment/emotions/ketou.gif "[ketou]")
![[shandian]](/static/assets/comment/emotions/shandian.gif "[shandian]")
![[haqian]](/static/assets/comment/emotions/haqian.gif "[haqian]")
![[jidong]](/static/assets/comment/emotions/jidong.gif "[jidong]")
![[zaijian]](/static/assets/comment/emotions/zaijian.gif "[zaijian]")
![[kafei]](/static/assets/comment/emotions/kafei.gif "[kafei]")
![[love]](/static/assets/comment/emotions/love.gif "[love]")
![[pizui]](/static/assets/comment/emotions/pizui.gif "[pizui]")
![[huitou]](/static/assets/comment/emotions/huitou.gif "[huitou]")
![[tiao]](/static/assets/comment/emotions/tiao.gif "[tiao]")
![[liwu]](/static/assets/comment/emotions/liwu.gif "[liwu]")
![[zhutou]](/static/assets/comment/emotions/zhutou.gif "[zhutou]")
![[e]](/static/assets/comment/emotions/e.gif "[e]")
![[qiang]](/static/assets/comment/emotions/qiang.gif "[qiang]")
![[youtaiji]](/static/assets/comment/emotions/youtaiji.gif "[youtaiji]")
![[zuohengheng]](/static/assets/comment/emotions/zuohengheng.gif "[zuohengheng]")
![[huaixiao]](/static/assets/comment/emotions/huaixiao.gif "[huaixiao]")
![[gouyin]](/static/assets/comment/emotions/gouyin.gif "[gouyin]")
![[keai]](/static/assets/comment/emotions/keai.gif "[keai]")
![[tiaosheng]](/static/assets/comment/emotions/tiaosheng.gif "[tiaosheng]")
![[daku]](/static/assets/comment/emotions/daku.gif "[daku]")
![[weiqu]](/static/assets/comment/emotions/weiqu.gif "[weiqu]")
![[lanqiu]](/static/assets/comment/emotions/lanqiu.gif "[lanqiu]")
![[zhemo]](/static/assets/comment/emotions/zhemo.gif "[zhemo]")
![[xia]](/static/assets/comment/emotions/xia.gif "[xia]")
![[fan]](/static/assets/comment/emotions/fan.gif "[fan]")
![[yun]](/static/assets/comment/emotions/yun.gif "[yun]")
![[youhengheng]](/static/assets/comment/emotions/youhengheng.gif "[youhengheng]")
![[chong]](/static/assets/comment/emotions/chong.gif "[chong]")
![[pijiu]](/static/assets/comment/emotions/pijiu.gif "[pijiu]")
![[dajiao]](/static/assets/comment/emotions/dajiao.gif "[dajiao]")
![[dao]](/static/assets/comment/emotions/dao.gif "[dao]")
![[diaoxie]](/static/assets/comment/emotions/diaoxie.gif "[diaoxie]")
![[liuhan]](/static/assets/comment/emotions/liuhan.gif "[liuhan]")
![[haha]](/static/assets/comment/emotions/haha.gif "[haha]")
![[xu]](/static/assets/comment/emotions/xu.gif "[xu]")
![[zhuakuang]](/static/assets/comment/emotions/zhuakuang.gif "[zhuakuang]")
![[zhuanquan]](/static/assets/comment/emotions/zhuanquan.gif "[zhuanquan]")
![[no]](/static/assets/comment/emotions/no.gif "[no]")
![[ok]](/static/assets/comment/emotions/ok.gif "[ok]")
![[feiwen]](/static/assets/comment/emotions/feiwen.gif "[feiwen]")
![[taiyang]](/static/assets/comment/emotions/taiyang.gif "[taiyang]")
![[woshou]](/static/assets/comment/emotions/woshou.gif "[woshou]")
![[zuqiu]](/static/assets/comment/emotions/zuqiu.gif "[zuqiu]")
![[xigua]](/static/assets/comment/emotions/xigua.gif "[xigua]")
![[hua]](/static/assets/comment/emotions/hua.gif "[hua]")
![[tu]](/static/assets/comment/emotions/tu.gif "[tu]")
![[tiaowu]](/static/assets/comment/emotions/tiaowu.gif "[tiaowu]")
![[ma]](/static/assets/comment/emotions/ma.gif "[ma]")
![[baiyan]](/static/assets/comment/emotions/baiyan.gif "[baiyan]")
![[zhadan]](/static/assets/comment/emotions/zhadan.gif "[zhadan]")
![[weixiao]](/static/assets/comment/emotions/weixiao.gif "[weixiao]")
![[wen]](/static/assets/comment/emotions/wen.gif "[wen]")
![[dabing]](/static/assets/comment/emotions/dabing.gif "[dabing]")
![[xianwen]](/static/assets/comment/emotions/xianwen.gif "[xianwen]")
![[shuijiao]](/static/assets/comment/emotions/shuijiao.gif "[shuijiao]")
![[yongbao]](/static/assets/comment/emotions/yongbao.gif "[yongbao]")
![[kelian]](/static/assets/comment/emotions/kelian.gif "[kelian]")
![[pingpang]](/static/assets/comment/emotions/pingpang.gif "[pingpang]")
![[danu]](/static/assets/comment/emotions/danu.gif "[danu]")
![[geili]](/static/assets/comment/emotions/geili.gif "[geili]")
![[wabi]](/static/assets/comment/emotions/wabi.gif "[wabi]")
![[kuaikule]](/static/assets/comment/emotions/kuaikule.gif "[kuaikule]")
![[zuotaiji]](/static/assets/comment/emotions/zuotaiji.gif "[zuotaiji]")
![[tuzi]](/static/assets/comment/emotions/tuzi.gif "[tuzi]")
![[bishi]](/static/assets/comment/emotions/bishi.gif "[bishi]")
![[caidao]](/static/assets/comment/emotions/caidao.gif "[caidao]")
![[dabian]](/static/assets/comment/emotions/dabian.gif "[dabian]")
![[fanu]](/static/assets/comment/emotions/fanu.gif "[fanu]")
![[guzhang]](/static/assets/comment/emotions/guzhang.gif "[guzhang]")
![[se]](/static/assets/comment/emotions/se.gif "[se]")
![[chajin]](/static/assets/comment/emotions/chajin.gif "[chajin]")
![[bizui]](/static/assets/comment/emotions/bizui.gif "[bizui]")
![[deyi]](/static/assets/comment/emotions/deyi.gif "[deyi]")
![[ku]](/static/assets/comment/emotions/ku.gif "[ku]")
![[huishou]](/static/assets/comment/emotions/huishou.gif "[huishou]")
![[yinxian]](/static/assets/comment/emotions/yinxian.gif "[yinxian]")
![[haixiu]](/static/assets/comment/emotions/haixiu.gif "[haixiu]")
Tonic Textual 替代方案
更多 替代方案-

-

-

試試 Textrics,一個基於強大人工智慧的文字分析工具,可以從文字中偵測出情緒、情緒、命名實體識別、標籤。透過最佳軟體,為您的企業帶來創新。
-

-
